调试你的BPF程序
这是一个实战系列文章,它是eBPF学习计划里面的应用场景之网络部分,终极目标是源码级别学习云原生网络方案Cilium(声明:下文提到的BPF字样是泛指,包括cBPF和eBPF)。
Cilium方案中大量使用了XDP、TC等网络相关的BPF hook,以实现高性能的网络RX和TX。
第一篇文章进行了XDP实战,XDP只能处理入站流量(正在接收的数据包)。为了处理出站流量(传输数据包出去),可以使用Traffic Control,简称TC,它是离网卡最近的可以控制全部流向的控制层。因此第二篇文章 进行了TC BPF实战。
这篇文章是解答上篇文章的留下的疑团。
目录
TL;DR
文章涉及的实验环境和代码可以到这个git repo获取:
https://github.com/nevermosby/linux-bpf-learning
问题
当停止了上篇文章实验中的XDP ingress hook,只保留TC egress hook时,使用命令curl localhost也是无法访问Nginx容器服务的?这是为什么呢?
解题思路
- 添加调试日志,打印通过目标网卡网络包的源地址(source address)和目标地址(destination address),观察是否符合现实情况;
- 单步调试,在加载到内核的BPF程序加断点(breakpoint),一旦被触发时,观察上下文的内容。
添加调试日志
第一种思路理论上是比较容易实现的,就是在适当的位置添加printf函数,但由于这个函数需要在内核运行,而BPF中没有实现它,因此无法使用。事实上,BPF程序能的使用的C语言库数量有限,并且不支持调用外部库。
使用辅助函数(helper function)
为了克服这个限制,最常用的一种方法是定义和使用BPF辅助函数,即helper function。比如可以使用bpf_trace_printk()辅助函数,这个函数可以根据用户定义的输出,将BPF程序产生的对应日志消息保存在用来跟踪内核的文件夹(/sys/kernel/debug/tracing/),这样,我们就可以通过这些日志信息,分析和发现BPF程序执行过程中可能出现的错误。
BPF默认定义的辅助函数有很多,它们都是非常有用的,可谓是「能玩转辅助函数,就能玩转BPF编程」。可以在这里找到全量的辅助函数清单。
使用bpf_trace_printk()辅助函数添加日志
这个函数的入门使用方法和输出说明可以在这篇文章中找到,现在我们把它加到BPF程序里。老规矩,直接上代码:
#include <stdbool.h>
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
#include <stdio.h>
#include "bpf_endian.h"
#include "bpf_helpers.h"
typedef unsigned int u32;
#define bpfprint(fmt, ...) \
({ \
char ____fmt[] = fmt; \
bpf_trace_printk(____fmt, sizeof(____fmt), \
##__VA_ARGS__); \
})
/*
check whether the packet is of TCP protocol
*/
static __inline bool is_TCP(void *data_begin, void *data_end){
bpfprint("Entering is_TCP\n");
struct ethhdr *eth = data_begin;
// Check packet's size
// the pointer arithmetic is based on the size of data type, current_address plus int(1) means:
// new_address= current_address + size_of(data type)
if ((void *)(eth + 1) > data_end) //
return false;
// Check if Ethernet frame has IP packet
if (eth->h_proto == bpf_htons(ETH_P_IP))
{
struct iphdr *iph = (struct iphdr *)(eth + 1); // or (struct iphdr *)( ((void*)eth) + ETH_HLEN );
if ((void *)(iph + 1) > data_end)
return false;
// extract src ip and destination ip
u32 ip_src = iph->saddr;
u32 ip_dst = iph->daddr;
//
bpfprint("src ip addr1: %d.%d.%d\n",(ip_src) & 0xFF,(ip_src >> 8) & 0xFF,(ip_src >> 16) & 0xFF);
bpfprint("src ip addr2:.%d\n",(ip_src >> 24) & 0xFF);
bpfprint("dest ip addr1: %d.%d.%d\n",(ip_dst) & 0xFF,(ip_dst >> 8) & 0xFF,(ip_dst >> 16) & 0xFF);
bpfprint("dest ip addr2: .%d\n",(ip_dst >> 24) & 0xFF);
// Check if IP packet contains a TCP segment
if (iph->protocol == IPPROTO_TCP)
return true;
}
return false;
}
SEC("xdp")
int xdp_drop_tcp(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
if (is_TCP(data, data_end))
return XDP_DROP;
return XDP_PASS;
}
SEC("tc")
int tc_drop_tcp(struct __sk_buff *skb)
{
bpfprint("Entering tc section\n");
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
if (is_TCP(data, data_end))
return TC_ACT_SHOT;
else
return TC_ACT_OK;
}
char _license[] SEC("license") = "GPL";
我们来一起看下更新的地方:
- 在代码开头,给
bpf_trace_printk定义了一个「替身」——定义了一个名为bpfprint的宏(如下所示),因为原始函数名称和参数有点冗长,这样做,便于后续使用简单。另外,函数体内使用了「可变参数宏」,这是C99标准才有的语法,想要深入了解的同学看这篇文章。 - 这个
bpfprint宏在代码里总共使用了6次。其中2处是字符串常量,用来标识程序运行到了相关的函数体内。另外4次是带有变量的:
这是非常有趣的4行代码,里面涉及到几个关键点:- 位运算和与运算,目的是把从网络上下文中拿到的32位integer类型的IP地址(源地址和目的地址)转换成可读的字符串类型(类似192.168.1.1)。如果在用户空间,这种转换可以通过
inet_ntoa这样的系统库进行操作,但是在内核空间下,由于没有这样的库函数,因此无法这样操作。那么,我们可以利用这个integer类型的存储本质,把代表IP地址每个段的数字「稀释」(这个词是本人自己想的,觉得挺贴切,如果有更好的,欢迎提出)出来。由于涉及的概念有点多,这其中的具体过程,将来独立写篇文章跟大家分享。 - 为什么需要用两行
bpfprint函数来打印一个IP地址?因为bpfprint函数只能接受4个参数,它背后的bpf_trace_printk函数只能接受5个参数,为什么呢?答案是跟BPF的底层架构有关,这里先按下不表。
- 位运算和与运算,目的是把从网络上下文中拿到的32位integer类型的IP地址(源地址和目的地址)转换成可读的字符串类型(类似192.168.1.1)。如果在用户空间,这种转换可以通过
- 眼尖的同学已经发现我们为内部函数
is_TCP添加了__inline关键词,这个是出于什么用意呢?大家不妨先猜测下,我们下文揭开谜团。
观察bpf_trace_printk()辅助函数打印的日志
代码侧已经添加好日志打印函数,那如何观察到日志输出呢?上文提到了一个专门记录日志的文件夹,里面的文件就是保持不同trace日志的。我们的bpf程序日志可以通过读取这个文件/sys/kernel/debug/tracing/trace_pipe:
# 它是一个流,会不停读取信息 cat /sys/kernel/debug/tracing/trace_pipe # 另一个种等价方式 tail -f /sys/kernel/debug/tracing/trace
解开egress网络谜团
我们只给主机侧的容器veth网卡加载tc egress的BPF程序(上面的代码),来看实际测试运行效果。
视频里的测试结果如下表格所示:
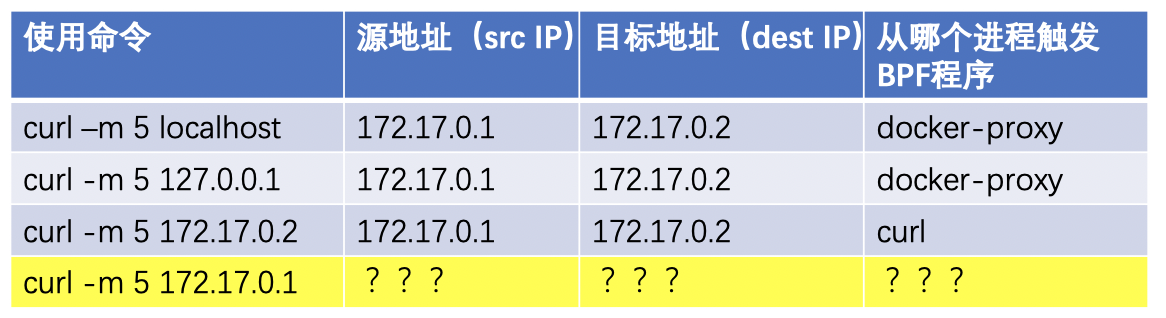
从上表格可以看出,前3条命令都会以源地址为172.17.0.1经过目标veth网卡,去向目的地址172.17.0.2(这个Nginx容器的私网地址),进而match到了BPF程序,然后符合期待地丢包了。
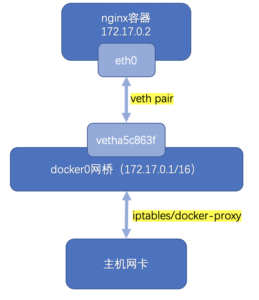
熟悉Docker容器网络同学看到了上面两个IP地址,可能就明白怎么一回事了。下面是我画的简版容器网络流向图,其中的关键点就是docker0网桥和主机侧的veth网卡其实是「一体」的,只要是访问容器内服务的,都会经过某个veth网卡,再访问具体的容器服务私网IP,这样就形成了veth网卡的egress流量。
考考大家,上面表格中的最后一行,你能填上正确的结果么?
解开新的谜团
上篇文章留下的疑团已经解开了,但这次的文章又出现了新的谜团:
bpf_trace_printk究竟能打印多少个参数?__inline关键字的作用是什么?
我们来一一分析。
深入分析辅助函数bpf_trace_printk
深入分析就必须看源代码了,先来看看这个函数的调用方式:
bpf_trace_printk(____fmt, sizeof(____fmt), ##__VA_ARGS__);
可以看出这个函数的前两个参数是相对固定的:
- 第一个是计划输出的字符串模板
- 第二个是这个字符串模板的长度
- 那么根据上文的代码,后面的可变参数宏就是最多可容纳3个的参数列表了
上文提到了看容纳的参数个数跟BPF底层架构有关,那是因为BPF底层是由11个64位寄存器、1个计数器和1个512字节BPF stack组成。寄存器命名规则是r0-r10,每个寄存器都有专属的作用:
- r0保存了调用一次辅助函数后的返回值
- r1 – r5 保存了从BPF程序到辅助函数的参数列表
- r6 – r9 是用来保存中间值的寄存器,它可以被多个辅助函数调用
- r10 是唯一的只读寄存器,包含访问BPF stack的指针
发现了么?BPF用来保存调用辅助函数的参数列表就是存放在r1 – r5这5个寄存器中,超过5个参数的调用目前是不支持的,因此只能workround下,多调用几次辅助函数,如同上文示例代码中所示。
第一个谜团已经解开了,在看第二谜团之前,我们来想一个问题,既然BPF辅助函数对于参数个数是有限制的,那一个BPF程序中调用BPF辅助函数会不会有限制?
答案是可能会有的。 这是什么意思呢?
这里就要说到BPF程序更多的限制了。BPF程序目前是无法使用普通共享库的,通常的做法是把BPF程序的常用库代码放在头文件中,然后在主程序中引用。
如果你确实想在主程序中使用函数调用(BPF to BPF function call),就像上文示例代码中的is_TCP,最佳实践是添加inline关键字,使这个函数成为内联函数,这样做的本质是,使得整个BPF程序编译后是一组连续的BPF指令,而不是非连续的,因为非连续的指令会导致BPF程序无法成功加载到内核。
可以到下面两个gist对比编译后的BPF指令:
- 没有使用内联的BPF程序编译后的指令:https://gist.github.com/nevermosby/f416fe021b4176117887804a0ce9dc70
- 使用内联后的BPF程序编译后的指令:https://gist.github.com/nevermosby/a182727870adb7cacb5d81a3570ce869
这样可能还不够,由于一些版本的编译器仍然可以「智能」地帮你决定是否取消内联大型的函数(这里就呼应了上文给出「可能会有」的答案),因此推荐使用always_inline关键词,保证编译器能严格按照我们的期待进行内联编译,上文示例代码的__inline关键字背后就是这样的一个宏定义:
#ifndef __inline # define __inline \ inline __attribute__((always_inline)) #endif
特别说明下,内核高于4.16配合LLVM 6.0以上,就可以天然支持主程序中使用函数调用(BPF to BPF function call)了,无需各种显式内联了。
如果你再细看bpf_trace_printk函数的源代码,其实还能看到更多信息(或者说是限制),比如字符串版本中只允许1个%s,详细代码看这里,我简单梳理了这个函数源代码的调用背景,有兴趣的同学可以深入看看。
除了bpf_trace_printk函数可以添加日志之外,还可以使用bpf_perf_event_output函数(如果你使用BCC,它的入口函数是BPF_PERF_OUTPUT),据说性能更好。
暂无通用的单步调试方案
很可惜,BPF目前没有通用的单步调试方案,你可能在互联网上发现一个bpf_dbg.c的方案,它是cBPF时代诞生的工具,分析pcap文件格式更友好(对,就是那个tcpdump的生成文件)。
下篇预告
既然在内核空间调试BPF有这个那个的限制,那么我们可不可以移到用户空间?这样就可以发挥各种瑞士军刀的作用了。
当然可以。
下一篇我们讲BPF map和bpftool。