你的第一个TC BPF 程序
这是一个实战系列文章,它是eBPF学习计划里面的应用场景之网络部分,终极目标是源码级别学习云原生网络方案Cilium(声明:下文提到的BPF字样是泛指,包括cBPF和eBPF)。
Cilium方案中大量使用了XDP、TC等网络相关的BPF hook,以实现高性能的网络RX和TX。
第一篇文章提到了XDP只能处理入站流量(正在接收的数据包)。为了处理出站流量(传输数据包出去),我们可以使用Traffic Control,简称TC,它是离网卡最近的可以控制全部流向的控制层。今天来实战TC BPF。
目录
TL;DR
文章涉及的实验环境和代码可以到这个git repo获取:
https://github.com/nevermosby/linux-bpf-learning
TC简介
TC全称「Traffic Control」,直译过来是「流量控制」,在这个领域,你可能更熟悉的是Linux iptables或者netfilter,它们都能做packet mangling,而TC更专注于packet scheduler,所谓的网络包调度器,调度网络包的延迟、丢失、传输顺序和速度控制。
TC优势
使用并配置TC,为用户带来了对于网络包的可预测性,减少对于网络资源的争夺,实现对不同优先等级的网络服务分配网络资源(如带宽),达到互不干扰的目的,因此服务质量(QoS)一词经常被用作TC的代名词。
TC劣势
配置复杂性成为使用TC最显著的缺点,如果配置TC得当,可以使网络资源分配更加公平。但一旦它以不恰当的方式配置使用,可能会导致资源的进一步争夺。因此相比学习如何正确配置TC,很多IT企业可能会倾向购买更高的带宽资源,
TC调度结构
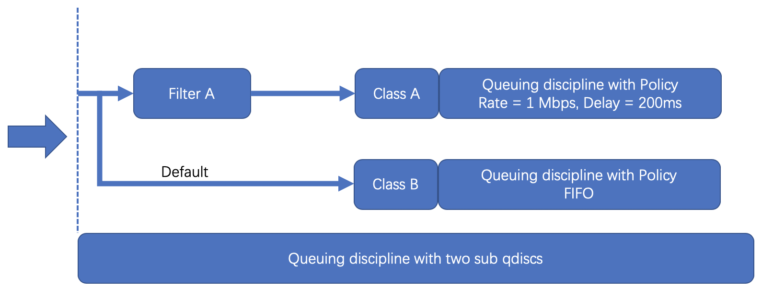
TC有4大组件:
- Queuing disciplines,简称为qdisc,直译是「队列规则」,它的本质是一个带有算法的队列,默认的算法是FIFO,形成了一个最简单的流量调度器。
- Class,直译是「种类」,它的本质是为上面的qdisc进行分类。因为现实情况下会有很多qdisc存在,每种qdisc有它特殊的职责,根据职责的不同,可以对qdisc进行分类。
- Filters,直译是「过滤器」,它是用来过滤传入的网络包,使它们进入到对应class的qdisc中去。
- Policers,直译是「规则器」,它其实是filter的跟班,通常会紧跟着filter出现,定义命中filter后网络包的后继操作,如丢弃、延迟或限速。
给大家上个图,了解下他们之间的关系:
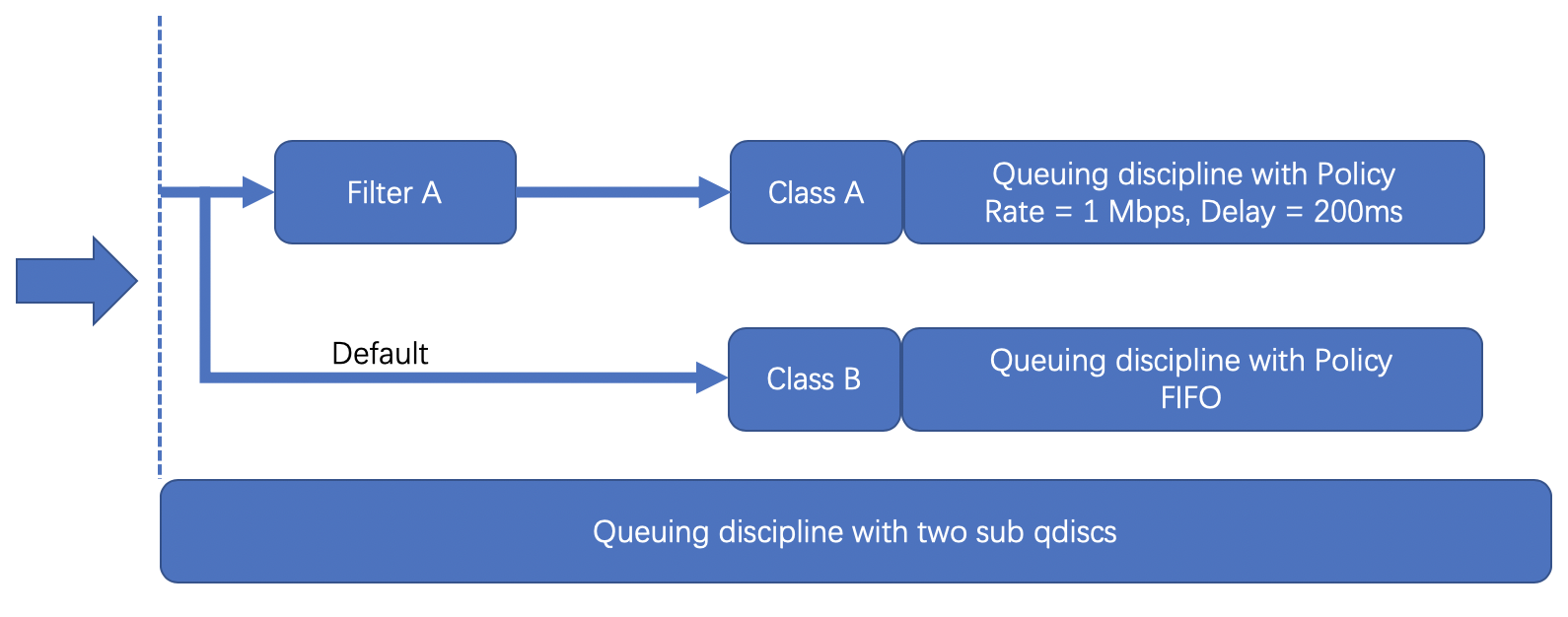
TC的调度结构远不止这么简单,大家感兴趣可以到这里看看更为详细的介绍。
那么TC是怎么和BPF联系在一起的呢?
从内核4.1版本起,引入了一个特殊的qdisc,叫做clsact,它为TC提供了一个可以加载BPF程序的入口,使TC和XDP一样,成为一个可以加载BPF程序的网络钩子。
TC vs XDP
这两个钩子都可以用于相同的应用场景,如DDoS缓解、隧道、处理链路层信息等。但是,由于XDP在任何套接字缓冲区(SKB)分配之前运行,所以它可以达到比TC上的程序更高的吞吐量值。然而,后者可以从通过 struct __sk_buff 提供的额外的解析数据中受益,并且可以执行 BPF 程序,对入站流量和出站流量都可以执行 BPF 程序,是 TX 链路上的能被操控的最一层。
TC内核代码结构
TC 输入参数
TC接受单个输入参数,类型为struct __sk_buff。这个结构是一种UAPI(user space API of the kernel),允许访问内核中socket buffer内部数据结构中的某些字段。它具有与 struct xdp_md 相同意义两个指针,data和data_end,同时还有更多信息可以获取,这是因为在TC层面上,内核已经解析了数据包以提取与协议相关的元数据,因此传递给BPF程序的上下文信息更加丰富。结构 __sk_buff 的整个声明如下所说,可以在 include/uapi/linux/bpf.h 文件中看到,下面是结构体的定义,比XDP的要多出很多信息,这就是为什么说TC层的吞吐量要比XDP小了,因为实例化一堆信息需要很大的cost。
* user accessible mirror of in-kernel sk_buff.
* new fields can only be added to the end of this structure
*/
struct __sk_buff {
__u32 len;
__u32 pkt_type;
__u32 mark;
__u32 queue_mapping;
__u32 protocol;
__u32 vlan_present;
__u32 vlan_tci;
__u32 vlan_proto;
__u32 priority;
__u32 ingress_ifindex;
__u32 ifindex;
__u32 tc_index;
__u32 cb[5];
__u32 hash;
__u32 tc_classid;
__u32 data;
__u32 data_end;
__u32 napi_id;
/* Accessed by BPF_PROG_TYPE_sk_skb types from here to ... */
__u32 family;
__u32 remote_ip4; /* Stored in network byte order */
__u32 local_ip4; /* Stored in network byte order */
__u32 remote_ip6[4]; /* Stored in network byte order */
__u32 local_ip6[4]; /* Stored in network byte order */
__u32 remote_port; /* Stored in network byte order */
__u32 local_port; /* stored in host byte order */
/* ... here. */
__u32 data_meta;
__bpf_md_ptr(struct bpf_flow_keys *, flow_keys);
__u64 tstamp;
__u32 wire_len;
__u32 gso_segs;
__bpf_md_ptr(struct bpf_sock *, sk);
};
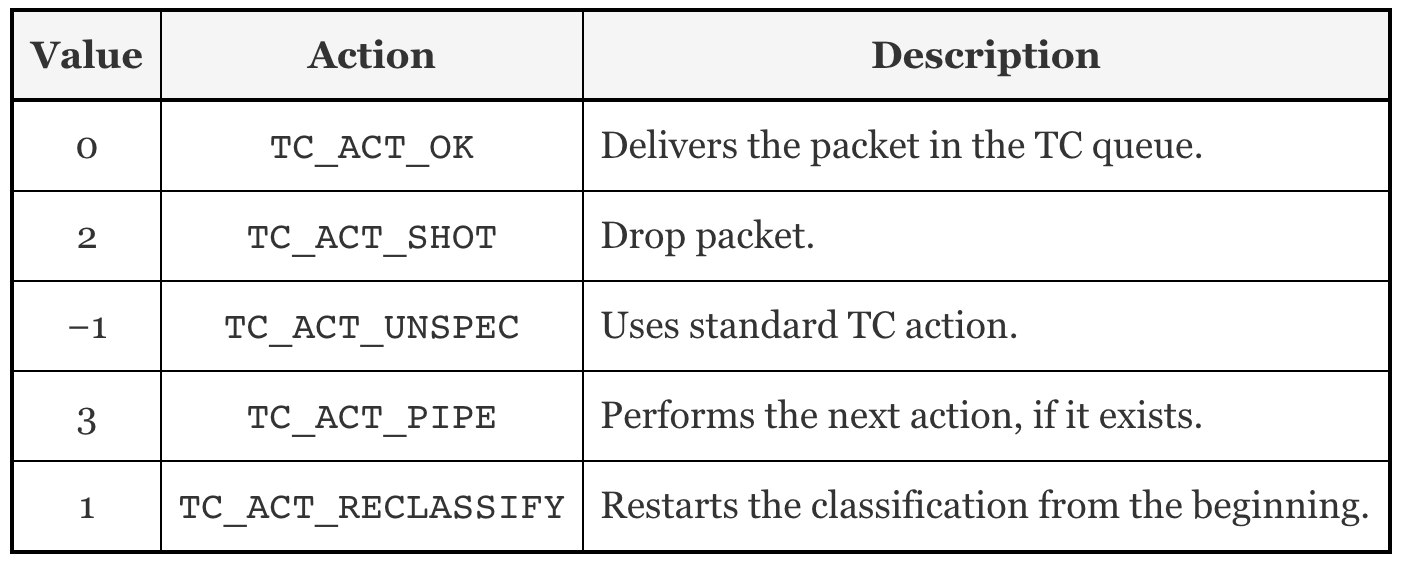
TC输出参数
和XDP一样,TC的输出代表了数据包如何被处置的一种动作。它的定义在include/uapi/linux/pkt_cls.h找到。最新的内核版本里定义了9种动作,其本质是int类型的值,以下是5种常用动作:
设计你的第一个TC程序
上文提到了,XDP是RX链路的第一层,TC是TX链路上的第一层,那么我们就设计一个同时使用这两个hook的程序,让他们一起发光发热,这次我们把流量粒度控制得更细点,实现把双向TCP流量都drop掉。
为了更贴近系列文章的初心——了解并学习容器网络Cilium的工作原理,我们这次拿容器实例作为流控目标。在实验环境上通过docker run运行一个Nginx服务:
docker run -d -p 80:80 --name=nginx-xdp nginx:alpine
这样主机层就会多出一个veth网络设备,与容器里的eth0形成veth pair,流量都是通过这对veth pair。因此我们可以将XDP程序attach到主机层的veth网络设备上,以此控制容器流量:
> ip a | grep veth 6: veth09e1d2e@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default # 加载XDP BPF程序 > ip link set dev veth09e1d2e xdp obj tc-xdp-drop-tcp.o sec xdp
由于我们需要测试双向流量,即也测试从容器内部访问外部网站,因此需要在容器内部执行curl命令,本人整理一篇如何从容器内部curl外部服务的文章,大家请移步查阅,这里不再赘述。
实战测试
这次我们先看实战结果,再来分析代码。
- 验证XDP只能控制RX流量(XDP完整实战指导看这里)
- 在主机层(Nginx容器外)curl Nginx容器的80端口
从Demo视频中看到,实现丢弃TCP流量的XDP程序attach到veth设备上后,就无法从外部访问基于HTTP协议的Nginx服务了(HTTP基于TCP)。
2. 在Nginx容器内部curl外部网站
可以看到视频在容器内访问百度网站是可达的,所以XDP程序不会影响从目标网卡出去的数据包。
从上面的例子可以看到XDP BPF程序只会对传给目标网卡的数据包进行丢弃,不会影响从目标网卡出去的数据包,也就是只影响ingress流量。
- 验证同时使用XDP和TC,控制RX和TX的TCP流量
如同XDP BPF程序可以通过ip命令进行加载,只要你安装了iproute2,也可以通过tc命令加载TC BPF程序。上文提到的了TC控制的单元是qdisc,用来加载BPF程序是个特殊的qdisc 叫clsact,示例命令如下所示:
# 为目标网卡创建clsact tc qdisc add dev [network-device] clsact # 加载bpf程序 tc filter add dev [network-device] <direction> bpf da obj [object-name] sec [section-name] # 查看 tc filter show dev [network-device] <direction>
简单说明下:
- 示例中有个参数<direction>,它表示将bpf程序加载到哪条网络链路上,它的值可以是ingress和egress。
- 还有一个不起眼的参数da,它的全称是direct-action。查看帮助文档:
direct-action | da instructs eBPF classifier to not invoke external TC actions, instead use the TC actions return codes (TC_ACT_OK, TC_ACT_SHOT etc.) for classifiers.
是不是看得一头雾水,这里先按下不表。
结合我们刚刚运行的Nginx容器实例,下面是实现TC BPF控制Egress的真真实命令:
# 最开始的状态 > tc qdisc show dev veth09e1d2e qdisc noqueue 0: root refcnt 2 # 创建clsact > tc qdisc add dev veth09e1d2e clsact # 再次查看,观察有什么不同 > tc qdisc show dev veth09e1d2e qdisc noqueue 0: root refcnt 2 qdisc clsact ffff: parent ffff:fff1 # 加载TC BPF程序到容器的veth网卡上 > tc filter add dev veth09e1d2e egress bpf da obj tc-xdp-drop-tcp.o sec tc # 再次查看,观察有什么不同 > tc qdisc show dev veth09e1d2e qdisc noqueue 0: root refcnt 2 qdisc clsact ffff: parent ffff:fff1 > tc filter show dev veth09e1d2e egress filter protocol all pref 49152 bpf chain 0 filter protocol all pref 49152 bpf chain 0 handle 0x1 tc-xdp-drop-tcp.o:[tc] direct-action not_in_hw id 24 tag 9c60324798bac8be jited
TC BPF程序加载好了,配上刚才控制Ingress的XDP程序,我们来看看效果:
代码分析
「Talk is cheap, show me the code」,来上代码。
// tc-xdp-drop-tcp.c
#include <stdbool.h>
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
#include "bpf_endian.h"
#include "bpf_helpers.h"
/*
check whether the packet is of TCP protocol
*/
static bool is_TCP(void *data_begin, void *data_end){
struct ethhdr *eth = data_begin;
// Check packet's size
// the pointer arithmetic is based on the size of data type, current_address plus int(1) means:
// new_address= current_address + size_of(data type)
if ((void *)(eth + 1) > data_end) //
return false;
// Check if Ethernet frame has IP packet
if (eth->h_proto == bpf_htons(ETH_P_IP))
{
struct iphdr *iph = (struct iphdr *)(eth + 1); // or (struct iphdr *)( ((void*)eth) + ETH_HLEN );
if ((void *)(iph + 1) > data_end)
return false;
// Check if IP packet contains a TCP segment
if (iph->protocol == IPPROTO_TCP)
return true;
}
return false;
}
SEC("xdp")
int xdp_drop_tcp(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
if (is_TCP(data, data_end))
return XDP_DROP;
return XDP_PASS;
}
SEC("tc")
int tc_drop_tcp(struct __sk_buff *skb)
{
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
if (is_TCP(data, data_end))
return TC_ACT_SHOT;
return TC_ACT_OK;
}
char _license[] SEC("license") = "GPL";
上面的代码里已经添加了相关注释帮助大家理解,我再针对几个关键点作下说明:
- 代码结构上定义了两个Section作为XDP和TC的入口,还有一个
is_TCP功能函数,判断是否是TCP网络包,供两个Section调用。这样做的好处是只要维护一份代码文件,根据Section名称,分别给XDP hook和TC hook加载。 - 这次的include的header文件很多,其中「
bpf_endian.h」和「bpf_helpers」是本地引用的头文件,其实是从内核代码的这个位置复制过来的,这个是参照了sample/bpf里面示例代码的做法。它们都是工具类函数集合,在写复杂逻辑时非常有用。 - 在
is_TCP这个函数里,有如下这一段:
if ((void *)(eth + 1) > data_end)
return false;
这个代码段第一次看肯定觉得有点无厘头。。。其实它有两层含义:
- 括号里运算式
eth+1是个非常有趣的表达式,它的本质是指针运算,指针变量+1就是指针向右移动n个字节,这个n为该指针变量指向的对象类型的字节长度,这里就是struct ethhdr的字节长度,为14个字节,可以在这个内核头文件里找到相关定义:
struct ethhdr {
// ETH_ALEN 为6个字节
unsigned char h_dest[ETH_ALEN]; /* destination eth addr */
unsigned char h_source[ETH_ALEN]; /* source ether addr */
// __be16 为16 bit,也就是2个字节
__be16 h_proto; /* packet type ID field */
}
// 所以整个struct就是14个字节长度。
如果不使用指针运算,还是作显式的长度判断,如下所示:
u64 h_offset;
struct ethhdr *eth = data;
// 显式声明并赋值ethhdr长度
h_offset = sizeof(*eth);
// 根据左右变量类型,运算符号加号重载成相关运算机制
if (data + h_offset > data_end)
return false;
另外,注意观察(eth + 1)前面加了一个显示类型转换,如果不做这个操作,编译时会有如下warning。代码里其他类似这样的显示类型转换都是出于规避编译warning的考虑。
warning: comparison of distinct pointer types
('struct ethhdr *' and 'void *') [-Wcompare-distinct-pointer-types]
if (eth + 1 > data_end)
~~~~~~~ ^ ~~~~~~~~
1 warning generated.
- 那整体的if语句判断目的是什么呢?目的是判断括号内运算结果会不会内存越界,这对于BPF验证器来说是必要的,如果没有,BPF验证器会阻止这个程序加载到内核中。由于我们需要通过右移
data变量获取到IP头,如下代码为获取IP头:
struct iphdr *iph = (struct iphdr *)(eth + 1);
因此需要判断这个右移结果是否有效,如果无效,就直接return出去了,防止内存越界。类似的右移判断逻辑在BPF程序里出现频次会很高,大家自己写BPF的时候,一定要做好边界判断逻辑。
编译代码
跟XDP程序一样,可以使用clang进行编译,不同之处是由于引用了本地头文件,所以需要加上-I参数,指定头文件所在目录:
clang -I ./headers/ -O2 -target bpf -c tc-xdp-drop-tcp.c -o tc-xdp-drop-tcp.o
加载到内核
将编译成功后输出的tc-xdp-drop-tcp.o文件,通过tc命令行加载到指定网卡设备上去。下面是使用verbose模式后的加载结果,可以看到BPF验证器通过检查tc-xdp-drop-tcp.o文件包含的BPF instructions,保障了加载到内核的安全性。
> tc filter add dev veth09e1d2e egress bpf da obj tc-xdp-drop-tcp.o sec tc verbose Prog section 'tc' loaded (5)! - Type: 3 - Instructions: 19 (0 over limit) - License: GPL Verifier analysis: 0: (61) r2 = *(u32 *)(r1 +80) 1: (61) r1 = *(u32 *)(r1 +76) 2: (bf) r3 = r1 3: (07) r3 += 14 4: (2d) if r3 > r2 goto pc+12 R1=pkt(id=0,off=0,r=14,imm=0) R2=pkt_end(id=0,off=0,imm=0) R3=pkt(id=0,off=14,r=14,imm=0) R10=fp0 5: (bf) r3 = r1 6: (07) r3 += 34 7: (2d) if r3 > r2 goto pc+9 R1=pkt(id=0,off=0,r=34,imm=0) R2=pkt_end(id=0,off=0,imm=0) R3=pkt(id=0,off=34,r=34,imm=0) R10=fp0 8: (71) r2 = *(u8 *)(r1 +13) 9: (67) r2 <<= 8 10: (71) r3 = *(u8 *)(r1 +12) 11: (4f) r2 |= r3 12: (57) r2 &= 65535 13: (55) if r2 != 0x8 goto pc+3 R1=pkt(id=0,off=0,r=34,imm=0) R2=inv8 R3=inv(id=0,umax_value=255,var_off=(0x0; 0xff)) R10=fp0 14: (b7) r0 = 2 15: (71) r1 = *(u8 *)(r1 +23) 16: (15) if r1 == 0x6 goto pc+1 R0=inv2 R1=inv(id=0,umax_value=255,var_off=(0x0; 0xff)) R2=inv8 R3=inv(id=0,umax_value=255,var_off=(0x0; 0xff)) R10=fp0 17: (b7) r0 = 0 18: (95) exit from 16 to 18: R0=inv2 R1=inv6 R2=inv8 R3=inv(id=0,umax_value=255,var_off=(0x0; 0xff)) R10=fp0 18: (95) exit from 13 to 17: safe from 7 to 17: safe from 4 to 17: safe processed 23 insns, stack depth 0
TC和BPF亲密合作
刚刚用到了一个参数da,它的全称是「direct action」。其实它是TC支持BPF后的「亲密合作」的产物。
对于tc filter来说,一般在命中过滤条件后需要指定下一步操作动作,如:
# 一个没有使用bpf的tc filter
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 \
match ip src 1.2.3.4 action drop
注意到这个tc filter后面跟了一个action drop,意思是命中过滤条件后将网络包丢弃,而这个操作动作如果我们使用BPF程序,其实就是已经定义在程序里了。为了避免重复指定,内核引入了da模式,告诉TC请repect BPF程序提供的返回值,无需再手动指定action了,节省了调用action模块的开销,这也是目前TC with BPF的推荐做法。这篇文章对此作了详细介绍。
意外的发现
当我开开心心准备结束本次实验时,突然发现当我停止了上面实验中的XDP ingress hook,只保留TC egress hook时,使用命令curl localhost也是无法访问Nginx容器服务的?(读者也可以自行试试)这是为什么呢?
需要解开这个问题,我们就需要调试BPF程序了。。。那么,下篇我们就来看看如何Debug BPF Program。