BPF数据传递的桥梁——BPF Map(一)
这是一个实战系列文章,它是eBPF学习计划里面的应用场景之网络部分,终极目标是源码级别学习云原生环境下使用eBPF的场景,比如Cilium、Falco等(声明:下文提到的BPF字样是泛指,包括cBPF和eBPF)。
本篇文章从源码级别学习BPF Map使用场景和工作原理,祝大家阅读愉快。
目录
TL;DR
文章涉及的实验环境和代码可以到这个git repo获取:
https://github.com/nevermosby/linux-bpf-learning/tree/master/bpf/bpf-maps
为什么需要BPF Map
通过消息传递来触发程序中的行为是软件工程中广泛使用的技术。一个程序可以通过发送消息来修改另一个程序的行为,这也允许这些程序之间通过这个方式来传递信息。
关于BPF最吸引人的一个方面,就是运行在内核上的程序可以在运行时使用消息传递相互通信,我称之为「communication on air」。
而BPF Map就是用户空间和内核空间之间的数据交换、信息传递的桥梁。
BPF Map是什么
BPF Map本质上是以「键/值」方式存储在内核中的数据结构,它们可以被任何知道它们的BPF程序访问。在内核空间的程序创建BPF Map并返回对应的文件描述符,在用户空间运行的程序就可以通过这个文件描述符来访问并操作BPF Map,这就是为什么BPF Map在BPF世界中是桥梁的存在了。
BPF Map类型
根据申请内存方式的不同,BPF Map有很多种类型(具体的列表可以看之前的博客文章),常用的类型是BPF_MAP_TYPE_HASH和BPF_MAP_TYPE_ARRAY,它们背后的内存管理方式跟我们熟悉的哈希表和数组基本一致,此外还有包括BPF_MAP_TYPE_PROG_ARRAY、BPF_MAP_TYPE_PERF_EVENT_ARRAY等10余种Map类型,具体可以查看之前的博文。随着多CPU架构的成熟发展,BPF Map也引入了per-cpu类型,如BPF_MAP_TYPE_PERCPU_HASH、BPF_MAP_TYPE_PERCPU_ARRAY等,当你使用这种类型的BPF Map时,每个CPU都会存储并看到它自己的Map数据,从属于不同CPU之间的数据是互相隔离的,这样做的好处是,在进行查找和聚合操作时更加高效,性能更好,尤其是你的BPF程序主要是在做收集时间序列型数据,如流量数据或指标等。
如何创建BPF Map
原生版BPF Map创建方式
union bpf_attr my_map_attr {
.map_type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 1024,
.map_flags = BPF_F_NO_PREALLOC,
};
int fd = bpf(BPF_MAP_CREATE, &my_map_attr, sizeof(my_map_attr));
上面是原生创建BPF Map的代码片段,最初创建BPF Map的方式都是通过bpf系统调用函数(上述代码第9行),传入的第一个参数是BPF_MAP_CREATE,它是创建BPF Map系统调用的代号,第二参数是指定将要创建Map的属性,第三个参数是这个Map配置的大小。因此创建Map之前首先要声明一个BPF Map(上述代码的第1-7行),其中有四大要素:
- Map类型(
map_type),就是上文提到的各种Map类型 - Map的键大小(
key_size),以字节为单位 - Map的值大小(
value_size),以字节为单位 - Map的元素最大容量(
max_entries),个数为单位
可以去到内核代码里看到相关定义:
union bpf_attr {
struct { /* anonymous struct used by BPF_MAP_CREATE command */
__u32 map_type; /* one of enum bpf_map_type */
__u32 key_size; /* size of key in bytes */
__u32 value_size; /* size of value in bytes */
__u32 max_entries; /* max number of entries in a map */
__u32 map_flags; /* BPF_MAP_CREATE related
* flags defined above.
*/
__u32 inner_map_fd; /* fd pointing to the inner map */
__u32 numa_node; /* numa node (effective only if
* BPF_F_NUMA_NODE is set).
*/
char map_name[BPF_OBJ_NAME_LEN];
};
除了四大要素之后,还有一些高级选项,其中map_flags作为可以调整Map创建行为的参数,使用频率也是越来越高。
创建BPF Map的返回值
上文示例代码的第9行中变量fd是创建BPF Map系统调用的返回值。正常情况下它的值是被成功创建出来的BPF Map的文件描述符(file descriptor)。非正常情况下,也就是系统调用失败,BPF Map没有被成功创建出来,返回值为-1,可以通过系统全局错误变量errno获取具体的错误信息,一般创建失败有3种原因:
- BPF Map定义的属性不正确,此时errno变量值为EINVAL;
- 当前用户没有足够权限执行相关操作,此时errno变量值为EPERM;
- 没有足够的内存空间来保存新创建BPF Map,此时errno变量值为ENOMEN;
简化版BPF Map创建方式
相对于直接使用bpf系统调用函数来创建BPF Map,在实际场景中常用的是一个简化版:
struct bpf_map_def SEC("maps") my_bpf_map = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 100,
.map_flags = BPF_F_NO_PREALLOC,
};
这个简化版看起来就是一个BPF Map声明,它是如何做到声明即创建的呢?关键点就是SEC("maps"),学名ELF惯例格式(ELF convention),它的工作原理是这样的:
- 声明ELF Section属性
SEC("maps")(之前的博文里有对Section作用的描述) - 内核代码
bpf_load.crespect目标文件中所有Section信息,它会扫描目标文件里定义的Section,其中就有用来创建BPF Map的SEC("maps"),我们可以到相关代码里看到说明:
// https://elixir.bootlin.com/linux/v4.15/source/samples/bpf/bpf_load.h#L41 /* parses elf file compiled by llvm .c->.o * . parses 'maps' section and creates maps via BPF syscall // 就是这里 * . parses 'license' section and passes it to syscall * . parses elf relocations for BPF maps and adjusts BPF_LD_IMM64 insns by * storing map_fd into insn->imm and marking such insns as BPF_PSEUDO_MAP_FD * . loads eBPF programs via BPF syscall * * One ELF file can contain multiple BPF programs which will be loaded * and their FDs stored stored in prog_fd array * * returns zero on success */ int load_bpf_file(char *path);
bpf_load.c扫描到SEC("maps")后,对BPF Map相关的操作是由load_maps函数完成,其中的bpf_create_map_node()和bpf_create_map_in_map_node()就是创建BPF Map的关键函数,它们背后都是调用了定义在内核代码tools/lib/bpf/bpf.c中的方法,而这个方法就是使用上文提到的BPF_MAP_CREATE命令进行的系统调用。- 最后在编译程序时,通过添加
bpf_load.o作为依赖库,并合并为最终的可执行文件中,这样在程序运行起来时,就可以通过声明SEC("maps")即可完成创建BPF Map的行为了。
从上面梳理的过程可以看到,这个简化版虽然使用了“语法糖”,但最后还是会去使用bpf()函数完成系统调用。
如何操作BPF Map
BPF Map也有自己的CRUD,除了bpf_map_create是创建BPF Map操作之外,下面列出了其他主要操作,
bpf_map_lookup_elem(map, key)函数,通过key查询BPF Map,得到对应valuebpf_map_update_elem(map, key, value, options)函数,通过key-value更新BPF Map,如果这个key不存在,也可以作为新的元素插入到BPF Map中去bpf_map_get_next_key(map, lookup_key, next_key)函数,这个函数可以用来遍历BPF Map,下文有具体的介绍。
这里只是简单罗列了操作BPF Map的函数名称,想具体了解函数使用场景的可以看这本书「linux-observability-with-bpf」的第3章节,这本书也有了中文版——「Linux内核观测技术BPF」,作为国内第一部关于BPF的技术书籍,感兴趣的都去支持下哦。

开发BPF Map示例程序
功能设计
还记得上一篇如何调试BPF程序的博文么,我们是通过bpf_trace_printk函数打印日志来调试程序,但是这个只能在内核空间使用的helper函数,其本身有很多限制,包括输出参数的个数有限、类型有限等。现在我们就可以借助BPF Map来完成相同的功能,即在内核空间收集网络包信息(源地址和目标地址),在用户空间展示这些信息,完成期待的程序「调试」工作。
代码设计
代码主要分两个部分:
- 一个是运行在内核空间的程序,主要功能为创建出定制版BPF Map,收集目标信息并存储至BPF Map中。
- 另一个是运行在用户空间的程序,主要功能为读取上面内核空间创建出的BPF Map里的数据,并进行格式化展示,以演示BPF Map在两者之间进行数据传递。
请注意,该程序的编译运行是基于Linux内核代码中BPF示例环境,如果你还不熟悉,可以参考这篇博文。
下面首先介绍运行在内核空间的示例代码:
#define KBUILD_MODNAME "foo"
#include <uapi/linux/bpf.h>
#include <uapi/linux/if_ether.h>
#include <uapi/linux/if_packet.h>
#include <uapi/linux/if_vlan.h>
#include <uapi/linux/ip.h>
#include <uapi/linux/in.h>
#include <uapi/linux/tcp.h>
#include <uapi/linux/udp.h>
#include "bpf_helpers.h"
#include "bpf_endian.h"
#include "xdp_ip_tracker_common.h"
#define bpf_printk(fmt, ...) \
({ \
char ____fmt[] = fmt; \
bpf_trace_printk(____fmt, sizeof(____fmt), \
##__VA_ARGS__); \
})
struct bpf_map_def SEC("maps") tracker_map = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(struct pair),
.value_size = sizeof(struct stats),
.max_entries = 2048,
};
static __always_inline bool parse_and_track(bool is_rx, void *data_begin, void *data_end, struct pair *pair)
{
struct ethhdr *eth = data_begin;
if ((void *)(eth + 1) > data_end)
return false;
if (eth->h_proto == bpf_htons(ETH_P_IP))
{
struct iphdr *iph = (struct iphdr *)(eth + 1);
if ((void *)(iph + 1) > data_end)
return false;
pair->src_ip = is_rx ? iph->daddr : iph->saddr;
pair->dest_ip = is_rx ? iph->saddr : iph->daddr;
// update the map for track
struct stats *stats, newstats = {0, 0, 0, 0};
long long bytes = data_end - data_begin;
stats = bpf_map_lookup_elem(&tracker_map, pair);
if (stats)
{
if (is_rx)
{
stats->rx_cnt++;
stats->rx_bytes += bytes;
}
else
{
stats->tx_cnt++;
stats->tx_bytes += bytes;
}
}
else
{
if (is_rx)
{
newstats.rx_cnt = 1;
newstats.rx_bytes = bytes;
}
else
{
newstats.tx_cnt = 1;
newstats.tx_bytes = bytes;
}
bpf_map_update_elem(&tracker_map, pair, &newstats, BPF_NOEXIST);
}
return true;
}
return false;
}
SEC("xdp_ip_tracker")
int _xdp_ip_tracker(struct xdp_md *ctx)
{
// the struct to store the ip address as the keys of bpf map
struct pair pair;
bpf_printk("starting xdp ip tracker...\n");
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
// pass if the network packet is not ipv4
if (!parse_and_track(true, data, data_end, &pair))
return XDP_PASS;
return XDP_DROP;
}
char _license[] SEC("license") = "GPL";
接下来是运行在用户空间的示例代码:
#include <linux/bpf.h>
#include <linux/if_link.h>
#include <assert.h>
#include <errno.h>
#include <signal.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/resource.h>
#include <arpa/inet.h>
#include <netinet/ether.h>
#include <unistd.h>
#include <time.h>
#include "bpf_load.h"
#include <bpf/bpf.h>
#include "bpf_util.h"
#include "xdp_ip_tracker_common.h"
static int ifindex = 6; // target network interface to attach, you can find it via `ip a`
static __u32 xdp_flags = 0;
// unlink the xdp program and exit
static void int_exit(int sig)
{
printf("stopping\n");
set_link_xdp_fd(ifindex, -1, xdp_flags);
exit(0);
}
// An XDP program which track packets with IP address
// Usage: ./xdp_ip_tracker
int main(int argc, char **argv)
{
char *filename = "xdp_ip_tracker_kern.o";
// change limits
struct rlimit r = {RLIM_INFINITY, RLIM_INFINITY};
if (setrlimit(RLIMIT_MEMLOCK, &r))
{
perror("setrlimit(RLIMIT_MEMLOCK, RLIM_INFINITY)");
return 1;
}
// load the kernel bpf object file
if (load_bpf_file(filename))
{
printf("error - bpf_log_buf: %s", bpf_log_buf);
return 1;
}
// confirm the bpf prog fd is available
if (!prog_fd[0])
{
printf("load_bpf_file: %s\n", strerror(errno));
return 1;
}
// add signal handlers
signal(SIGINT, int_exit);
signal(SIGTERM, int_exit);
// link the xdp program to the network interface
if (set_link_xdp_fd(ifindex, prog_fd[0], xdp_flags) < 0)
{
printf("link set xdp fd failed\n");
return 1;
}
int result;
struct pair next_key, lookup_key = {0, 0};
struct stats value = {};
while (1)
{
sleep(2);
// retrieve the bpf map of statistics
while (bpf_map_get_next_key(map_fd[0], &lookup_key, &next_key) != -1)
{
//printf("The local ip of next key in the map is: '%d'\n", next_key.src_ip);
//printf("The remote ip of next key in the map is: '%d'\n", next_key.dest_ip);
struct in_addr local = {next_key.src_ip};
struct in_addr remote = {next_key.dest_ip};
printf("The local ip of next key in the map is: '%s'\n", inet_ntoa(local));
printf("The remote ip of next key in the map is: '%s'\n", inet_ntoa(remote));
// get the value via the key
// TODO: change to assert
// assert(bpf_map_lookup_elem(map_fd[0], &next_key, &value) == 0)
result = bpf_map_lookup_elem(map_fd[0], &next_key, &value);
if (result == 0)
{
// print the value
printf("rx_cnt value read from the map: '%llu'\n", value.rx_cnt);
printf("rx_bytes value read from the map: '%llu'\n", value.rx_bytes);
}
else
{
printf("Failed to read value from the map: %d (%s)\n", result, strerror(errno));
}
lookup_key = next_key;
printf("\n\n");
}
printf("start a new loop...\n");
// reset the lookup key for a fresh start
lookup_key.src_ip = 0;
lookup_key.dest_ip = 0;
}
printf("end\n");
// unlink the xdp program
set_link_xdp_fd(ifindex, -1, xdp_flags);
return 0;
}
分析代码
我们先来看运行在内核空间的BPF程序代码重点内容:
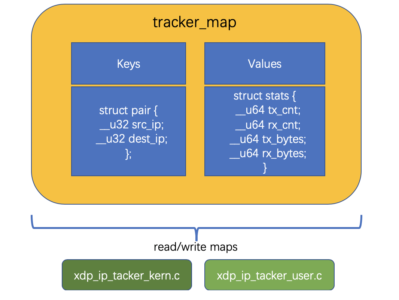
1、通过SEC("maps")声明并创建了一个名为tracker_map 的BPF Map,它的类型是BPF_MAP_TYPE_HASH,它的key和value都是自定义的struct,定义在了xdp_ip_tracker_common.h头文件中,具体如下所示。你可以基于自定义struct,实现灵活的数据结构设计,比起之前使用bpf_trace_printk函数只能使用单一的数据类型,will make you smile again.
#include <linux/types.h>
// define the struct for the key of bpf map
struct pair {
__u32 src_ip;
__u32 dest_ip;
};
// define the struct for the value of bpf map
struct stats {
__u64 tx_cnt; // the sending request count
__u64 rx_cnt; // the received request count
__u64 tx_bytes; // the sending request bytes
__u64 rx_bytes; // the sending received bytes
};
2、函数parse_and_track是对网络包进行分析和过滤,把源地址和目的地址联合起来作为BPF Map的key,把当前网络包的大小以byte单位记录下来,并联合网络包计数器作为BPF Map的value。对于连续的网络包,如果生成的key已经存在,就把value累加,否则就新增一对key-value存入BPF Map中。其中通过bpf_map_lookup_elem()函数来查找元素,bpf_map_update_elem()函数来新增元素。
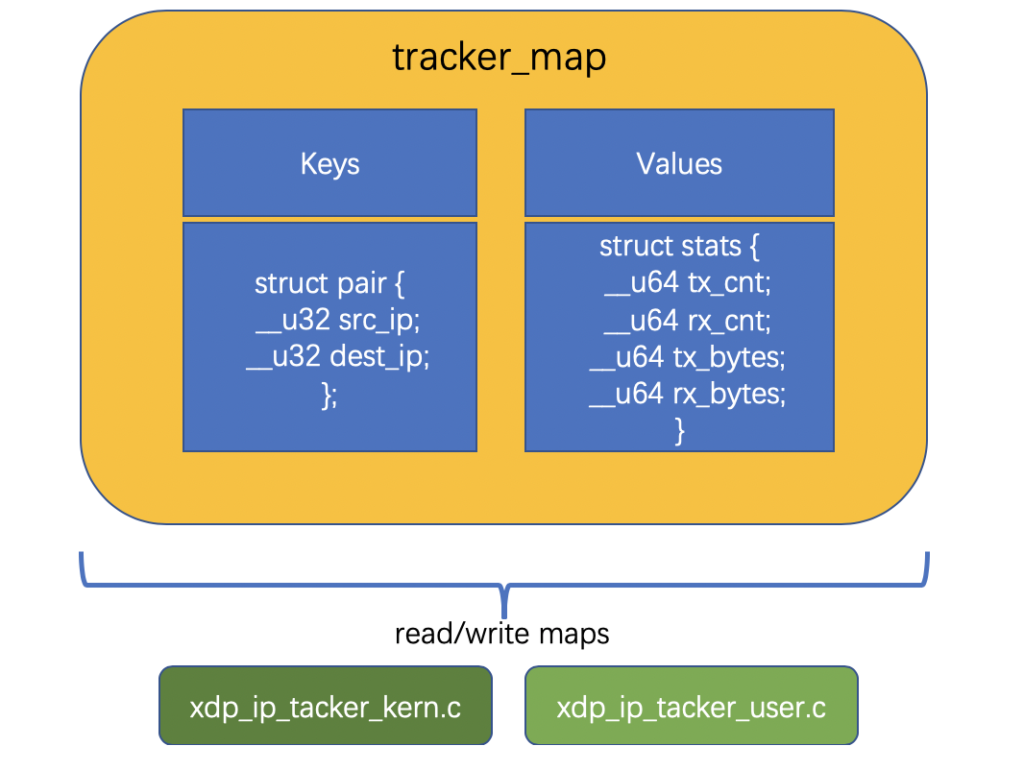
我们再来看运行在用户空间程序代码的重点内容:
- 用户空间的代码跟一般看到的C程序的结构是一样的,都是有main函数作为入口。基本流程是,通过
load_bpf_file()函数(本质就是用BPF_PROG_LOAD命令进行系统调用)加载对应内核空间的BPF程序编译出来的.o文件,这种通过编程加载BPF程序的方式,和我们之前通过命令行工具的方式相比,更具灵活性,适合实际场景中的产品分发。 - 加载完BPF程序之后,使用
set_link_xdp_fd()函数attach到目标hook上,看函数名就知道了,这是XDP network hook。它接受的两个主要的参数是:ifindex,这个是目标网卡的序号(可以通过ip a查看),我这里填写的是6,它是对应了一个docker容器的veth虚拟网络设备;prog_fd[0],这个是BPF程序加载到内存后生成的文件描述符fd。
- 有两个神奇的变量
prog_fd和map_fd得说明下:- 它们都是定义在
bpf_load.c的全局变量; -
prog_fd是一个数组,在加载内核空间BPF程序时,一旦fd生成后,就添加到这个数组中去; map_fd也是一个数组,在运行上文提到的load_maps()函数时,一旦完成创建BPF Map系统调用生成fd后,同样会添加到这个数组中去。 因此在bpf sample文件夹下的程序可以直接使用这两个变量,作为对于BPF程序和BPF Map的引用。
- 它们都是定义在
- 从代码71行开始是一个无限循环,里面是每2秒获取一下目标BPF Map的数据。获取的逻辑是通过
bpf_map_get_next_key(map_fd[0], &lookup_key, &next_key)函数,map_fd[0]是你的目标BPF Map;lookup_key是需要查找的BPF Map目标key,这个参数是要主动传入的,而next_key是这个目标key相邻的下一个key,这个参数是被动赋值的。如果你想从头开始遍历BPF Map,就可以通过传入一个一定不存在的key作为lookup_key,然后next_key会被自动赋值为BPF Map中第一个key,key知道了,对应的value也就可以被读取了,直到bpf_map_get_next_key()返回为-1,即next_key没有可以被赋值的了,遍历也就完成了,这个函数工作起来是不是像一个iterator。
通过上面两层循环,不停遍历BPF Map并打印里面的内容,一旦有新的网络包进来,也能及时获取到相关信息。
还有一段非常陌生的代码,如下所示:
struct rlimit r = {RLIM_INFINITY, RLIM_INFINITY};
if (setrlimit(RLIMIT_MEMLOCK, &r))
{
perror("setrlimit(RLIMIT_MEMLOCK, RLIM_INFINITY)");
return 1;
}
- 这里有一个struct叫
rlimit,全称是resource limit,顾名思义,它是控制应用进程能使用资源的限额。 - 常量
RLIM_INFINITY看起来就是无限的意思,因此第一行代码就是定义了一个没有上限的资源配额。 - 第二行代码使用了函数
setrlimit(),传入的第一个参数是一个资源规格名称——RLIMIT_MEMLOCK,即内存;第二个参数是刚才定义的无限资源配额,可以猜出这行代码的意思就是为内存资源配置了无限配额,即没有内存上限。 - 为什么要把内存限制放开呢?因为操作系统在不同的CPU架构,对于应用进程能使用的内存限制是不统一的,而不同的BPF程序需要使用到的内存资源也是可变的,比如你的BPF Map申请了很大的
max_entries,那么这个BPF程序一定会使用不少的内存。因此为了成功运行BPF程序,就把对于内存的限制放开成无限了。
想了解更多关于rlimit的信息,可以看这篇博文。
示例程序的运行效果
上视频
BPF Map背后的fd分析
在Unix/Linux的世界,一切皆是文件,BPF Map也不例外。从上文看到我们是可以通过文件描述符fd来访问BPF Map内的数据,因此BPF Map创建是遵循Linux文件创建的过程。实现BPF_MAP_CREATE系统调用命令的函数是map_create(),即创建BPF Map的核心函数:
// https://elixir.bootlin.com/linux/v4.15/source/kernel/bpf/syscall.c#L383
static int map_create(union bpf_attr *attr)
{
int numa_node = bpf_map_attr_numa_node(attr);
struct bpf_map *map;
int f_flags;
int err;
err = CHECK_ATTR(BPF_MAP_CREATE);
if (err)
return -EINVAL;
f_flags = bpf_get_file_flag(attr->map_flags);
if (f_flags < 0)
return f_flags;
if (numa_node != NUMA_NO_NODE &&
((unsigned int)numa_node >= nr_node_ids ||
!node_online(numa_node)))
return -EINVAL;
/* find map type and init map: hashtable vs rbtree vs bloom vs ... */
map = find_and_alloc_map(attr);
if (IS_ERR(map))
return PTR_ERR(map);
err = bpf_obj_name_cpy(map->name, attr->map_name);
if (err)
goto free_map_nouncharge;
atomic_set(&map->refcnt, 1);
atomic_set(&map->usercnt, 1);
err = security_bpf_map_alloc(map);
if (err)
goto free_map_nouncharge;
err = bpf_map_charge_memlock(map);
if (err)
goto free_map_sec;
err = bpf_map_alloc_id(map);
if (err)
goto free_map;
// assign a fd for bpf map
err = bpf_map_new_fd(map, f_flags);
if (err < 0) {
/* failed to allocate fd.
* bpf_map_put() is needed because the above
* bpf_map_alloc_id() has published the map
* to the userspace and the userspace may
* have refcnt-ed it through BPF_MAP_GET_FD_BY_ID.
*/
bpf_map_put(map);
return err;
}
trace_bpf_map_create(map, err);
return err;
free_map:
bpf_map_uncharge_memlock(map);
free_map_sec:
security_bpf_map_free(map);
free_map_nouncharge:
map->ops->map_free(map);
return err;
}
其中bpf_map_new_fd()函数就是用来为BPF Map分配fd的,下面是其函数主体:
// https://elixir.bootlin.com/linux/v4.15/source/kernel/bpf/syscall.c#L327
int bpf_map_new_fd(struct bpf_map *map, int flags)
{
int ret;
ret = security_bpf_map(map, OPEN_FMODE(flags));
if (ret < 0)
return ret;
/**
* anon_inode_getfd - creates a new file instance by hooking it up to an
* anonymous inode, and a dentry that describe the "class"
* of the file
*
* @name: [in] name of the "class" of the new file
* @fops: [in] file operations for the new file
* @priv: [in] private data for the new file (will be file's private_data)
* @flags: [in] flags
*
* Creates a new file by hooking it on a single inode. This is useful for files
* that do not need to have a full-fledged inode in order to operate correctly.
* All the files created with anon_inode_getfd() will share a single inode,
* hence saving memory and avoiding code duplication for the file/inode/dentry
* setup. Returns new descriptor or an error code.
*/
return anon_inode_getfd("bpf-map", &bpf_map_fops, map,
flags | O_CLOEXEC);
}
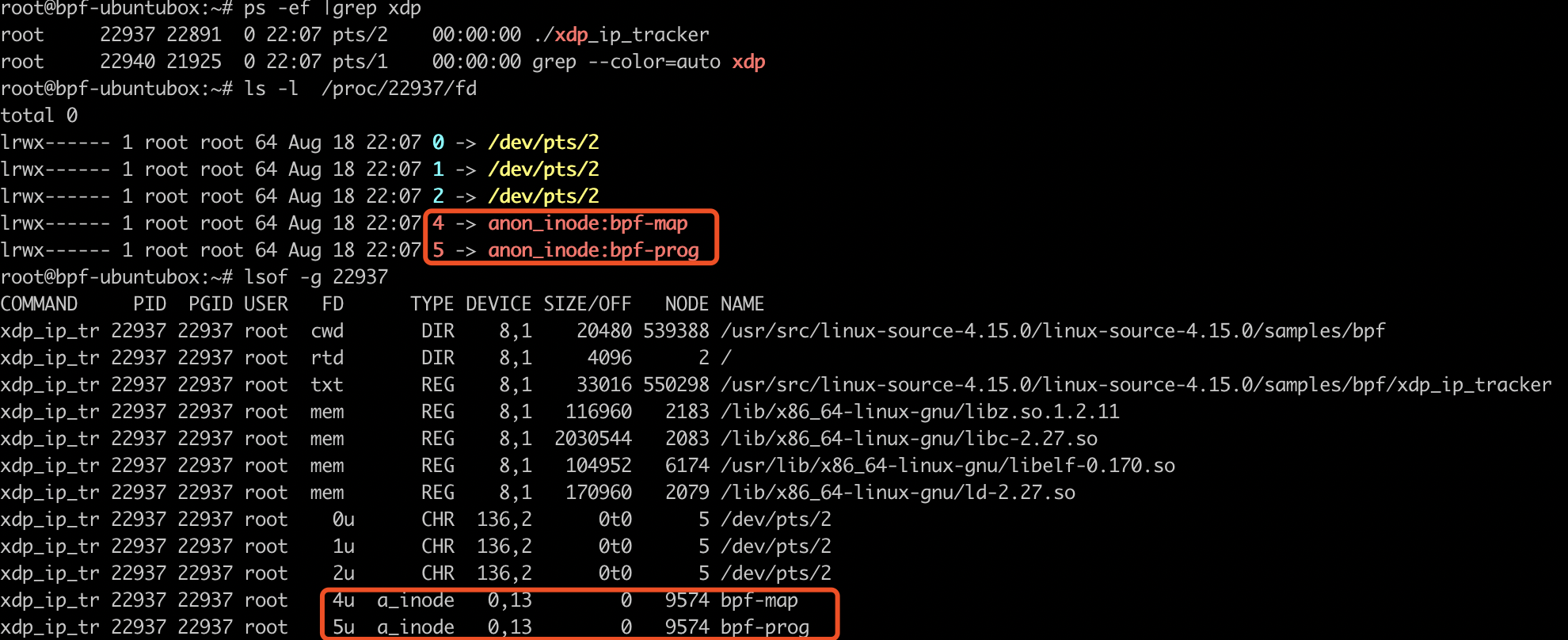
要说的是anon_inode_getfd()这个函数,它不是一般的分配fd的方式,是一种特殊的匿名(anonymous)方式,它的inode没有被绑定到磁盘上的某个文件,而是仅仅在内存里。一旦fd关闭后,对应的内存空间就会被释放,相关数据,即我们的BPF Map也就被删除了。它的comment doc写得非常好,详细大家可以自行了解。
也可以通过lsof和cat /proc/[pid]/fd命令看到BPF Map作为anon_inode的效果(其实普通的BPF程序也是这个type):
查看正在使用的BPF Map
如果想看当前操作系统上面是否有正在使用BPF Map,可以使用BPF社区大力推荐的命令行工具——BPFtool,它是专门用来查看BPF程序和BPF Map的命令行工具,并且可以对它们做一些简单操作。BPFtool源码被维护在Linux内核代码里(可见其重要性),因此一般都是通过make命令自行编译出可执行文件,操作起来并不麻烦,如下所示:
cd linux-source-code/tools make -C bpf/bpftool/ cd bpf/bpftool/ // the output is a binary named as `bpftool` ./bpftool [prog|map]
需要注意的是,不同内核版本下的BPFtool代码有所差异,其功能也不一样,一般来说高版本内核下的BPFtool功能更多,也是向下兼容的。我使用的就是在5.6.6内核版本下编译出来的BPFtool,并且在内核版本是4.15.0操作系统上运行顺畅。
使用BPFtool查看BPF Map信息
接下来给大家简单演示如何使用bpftool查看BPF Map信息,主要用两个命令进行查看:
# command #1, list all the bpf map in the current node # you can find map id, map type, map name, key type, value type, the number of max entry and memory allocation in the output > bpftool map 29: hash name tracker_map flags 0x0 key 8B value 32B max_entries 2048 memlock 217088B # command #2, show the bpf map details including keys and value in hex-format # the map id can be found in the output of command #1 # you can also find the element number > bpftool map dump id [map id] key: c0 a8 3a 01 ac 11 00 02 value: 00 00 00 00 00 00 00 00 0a 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 e4 02 00 00 00 00 00 00 key: ac 11 00 01 ac 11 00 02 value: 00 00 00 00 00 00 00 00 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 06 02 00 00 00 00 00 00 Found 2 elements
以下演示两个场景的BPF Map信息:
- 当前的实验环境(ubuntu 18.04 with kernel 4.15.0),正在运行上文的示例程序:
注:这个环境的BPFTool命名为hbpftool,因为它来自于更高版本的内核,区别于当前内核版本下的bpftool。 - 一个部署了Cilium网络方案的kubernetes工作节点
可以看到Cilium创建了很多BPF Map,主要是hash和prog_array两个类型,存储了大量信息用来实现kube-proxy组件的功能,待深入学习后会单独写系列文章出来。
BPFtool其实功能非常丰富,后面还会使用到它,大家感兴趣的可以去这里看看更多功能介绍。
彩蛋
讲了上面的BPF Map背后原理,可以看到只要能知晓BPF Map的fd就能访问里面的数据,那么其他非BPF程序是否也能访问BPF Map?答案是肯定的,这次的彩蛋,就给大家介绍一个来自于腾讯云团队的使用IPVS模块操作BPF Map的例子,大致技术是这样的:
当前 Kubernetes Service 的主流方案采用 IPVS 和 iptables 的混合模式,IPVS实现后端pod之间负载均衡,而由于IPVS没有实现SNAT功能,就使用了iptables辅助实现 SNAT。这种组合性能并不理想,原因在于 iptables 完成了很多通用功能,对于单纯使用SNAT 而言显得过于复杂,造成性能损耗。 为了解决这个问题,腾讯云通过 eBPF 扩展了 IPVS 的功能,新方案用 eBPF 程序实现 SNAT 功能,并修改 IPVS 内核源码与 eBPF 密切配合,实现了 FULL-NAT 的负载均衡器。详细的内容可以查看这篇文章。
在腾讯云的技术实现细节中,就有通过IPVS模块向BPF Map插入数据的逻辑,其关键代码如下所示:
// https://github.com/Tencent/TencentOS-kernel/blob/master/net/netfilter/ipvs/ip_vs_bpf_proc.c#L56
struct bpf_map *conntrack_map;
// https://github.com/Tencent/TencentOS-kernel/blob/master/net/netfilter/ipvs/ip_vs_bpf_proc.c#L402
static ssize_t ip_vs_bpf_write(struct file *file,
const char __user *ubuf,
size_t count,
loff_t *ppos)
{
int err = 0;
struct bpf_map *map = NULL;
struct bpf_prog *prog1 = NULL;
struct bpf_prog *prog2 = NULL;
const char delim[2] = ":";
char ids[5][20];
char *token;
int tag, pid;
unsigned int mapid, progid1, progid2;
char buf[100];
int i = 0;
char *s = buf;
...
/* singleton:conntrack_map is assigned once,
* and be nulled in module exit
*/
if (conntrack_map) {
pr_err("%s %d conntrack_map exists\n",
__func__, __LINE__);
return -EEXIST;
}
...
err = bpf_conntrack_map_get(pid, mapid,
(long long)(resolve_addrs.bpf_map_fops),
&map);
if (err != 0 || !map) {
pr_err("%s acquire bpf_map failed\n", __func__);
return -EINVAL;
}
...
bpf_map_fd = mapid;
...
// got the target bpf map via fd
conntrack_map = map;
...
}
// https://github.com/Tencent/TencentOS-kernel/blob/master/net/netfilter/ipvs/ip_vs_bpf_proc.c#L306
static int bpf_conntrack_map_get(int pid,
unsigned int fd,
unsigned long long addr,
struct bpf_map **map)
{
struct files_struct *files;
struct task_struct *task;
struct file *file;
int err = 0;
...
file = fcheck_files(files, fd);
...
*map = file->private_data;
if (*map)
bpf_map_inc2(*map);
...
}
简单说明下ip_vs_bpf_proc.c文件:
- 在
ip_vs_bpf_proc.c这个文件开头声明了一个bpf_map结构(来自内核bpf体系)的变量conntrack_map,这个就是将来被IPVS操作的BPF Map对象。 - 同样是在
ip_vs_bpf_proc.c这个文件里,函数ip_vs_bpf_write()内调用了bpf_conntrack_map_get()方法,而它的入参之一mapid在这里就是BPF Map的fd,这个方法内容就是通过fd找到了背后相关数据,并序列化为bpf_map结构的对象,最终赋值给conntrack_map,完成目标BPF Map的获取。
然后在IPVS模块创建新connection时,对上面conntrack_map插入了必要的元素,关键代码如下所示:
// https://github.com/Tencent/TencentOS-kernel/blob/master/net/netfilter/ipvs/ip_vs_conn.c#L1098
static bool ip_vs_conn_new_bpf(struct ip_vs_dest *dest,
unsigned int flags,
const struct ip_vs_conn_param *p,
int *skip)
{
int i;
struct ip_vs_service *svc;
struct bpf_lb_conn_key key = {};
struct bpf_lb_conn_key reply_key = {};
struct bpf_lb_conn_value value = {};
struct bpf_lb_conn_value reply_value = {};
struct bpf_lb_conn_value *v;
int inserted = 0;
struct bpf_map *map;
...
if (!bpf_mode_on)
return true;
...
// conntrack_map is the same one
map = conntrack_map;
...
lip = alloc_localip();
reply_key.sip = key.dip;
reply_key.sport = key.dport;
reply_key.dip = lip;
reply_key.dport = key.sport;
reply_key.proto = p->protocol;
reply_key.vip = 0;
reply_key.vport = 0;
reply_key.pad = 0;
atomic_set(&reply_value.ref, 0);
reply_value.sip = key.dip;
reply_value.sport = key.dport;
reply_value.dip = key.sip;
reply_value.dport = key.sport;
reply_value.proto = p->protocol;
...
if (likely(!map->ops->map_lookup_elem(map, &reply_key))) {
if (likely(map->ops->map_update_elem(map,
&reply_key,
&reply_value,
BPF_ANY) == 0)) {
/* the common case! break the loop */
inserted = 1;
nf_conntrack_single_unlock(&reply_key,
map->key_size);
break;
}
/* if lookup ok, shall insert ok since lock is held!*/
pr_err("map insert key failed\n");
BPF_STAT_INC(p->ipvs, BPF_NEW_INSERT);
nf_conntrack_single_unlock(&reply_key, map->key_size);
return false;
}
...
}
在上面的代码里使用了map_lookup_elem()和map_update_elem()两个操作BPF Map的方法——先查询后更新(插入新的元素),完成对BPF Map的操作。
是不是很有趣?
下篇预告——如何持久化BPF Map数据
上面讲到了BPF Map生命周期是跟着它的fd,当它所在的BPF程序运行结束后,fd也就关闭了,Map数据就没了?
如果开发者觉得BPF Map数据很重要,希望持久保留,该怎么办呢?社区大佬听到开发者的心声,大手一挥,实现了BPF Map数据持久化。详情请听下回分解。
bpf map的持久化文章,还有cilium的解析,怎么没写了,大佬?期待大作呀
draft有了,定稿中,在抽时间完成,感谢催更😂
期待大作+1
给大佬打call ,催更
感谢提供这么好的分享,期待加快更新速度
谢谢夸奖,尽力填坑中
在bpf kernel代码里面,直接调用bpf_map_lookup_elem,第一个参数传的是一个fd, 像xdp程序,进程上下文可能不是用户态xdp程序了,是怎么获取到正确的bpf_map呢?
写的真好