eBPF文章翻译(3)——XDP原始设计介绍
eBPF学习计划可以看这里。
原文名称:Early packet drop — and more — with BPF,原文地址:https://lwn.net/Articles/682538/。
为了更好地理解XDP设计,翻译了这篇XDP原始设计的介绍。
目录
Early packet drop — and more — with BPF 更早的丢包方式—还有更多—通过BPF
伯克利数据包过滤器(BPF)机制自2014年被重写和扩展(eBPF)以来,一直在各种内核子系统中发挥作用。事实证明,通过在内核虚拟机,允许在不编写内核自身代码的情况下实现任意策略的方式,存在着巨大的价值。最近一个将BPF推向网络驱动程序的补丁集显示了这种机制的一些潜力—以及集成一种经得起时间考验的方式的设计难度。如果成功的话,它可能会改变Linux系统上的实现高性能网络方式。
Early drop 更早丢弃
这个由Brenden Blanco提供的补丁集,从某种意义上说,是对BPF最初目的的回归:选择网络数据包,接受或拒绝。不过,现在的这个情况,是让这种选择发生在「译者注:网络数据包传入主机后」最早的时间点:即一旦收到数据包,就在网络适配器设备驱动中进行选择。这样做的目的是为了尽可能廉价地处理注定被丢弃的数据包,最好是在做任何协议处理工作之前,例如为这些数据包建立一个sk_buff结构(SKB)「译者注:全称为socket buffer」。
由系统调用函数 bpf()加载的BPF程序,有一个与之相关联的类型;在加载一个程序进行特定任务之前,会检查该类型。Brenden的补丁集首先定义了一个新的类型,BPF_PROG_TYPE_PHYS_DEV,用于在早期执行数据包处理的程序。每个程序类型都包括一个 “上下文”,它是在程序运行时产生的信息;在这种情况下,上下文需要包括有关正在审核的数据包信息。在内部,这个上下文由 struct xdp_metadata 表示;在这个版本的补丁集中,它只包含数据包的长度。
下一步是添加一个新的方法net_device_ops,以便驱动程序可以应用:
int (*ndo_bpf_set)(struct net_device *dev, int fd);
调用ndo_bpf_set()告诉驱动程序安装由给定的文件描述符fd所指示的bpf程序;新安装程序会替换现有的程序(如果有的话)。一个负的fd值意味着任何现有的程序都应该被删除。有一个新的netlink操作,允许在用户空间为给定的网络设备上设置程序。
驱动程序可以使用bpf_prog_get()从文件描述符中获得指向实际BPF程序的指针。当一个数据包传来时,可以使用BPF_PROG_RUN()宏函数对该数据包运行程序;来自程序的非零返回码,表明该数据包应该被丢弃。
Just a starting point 这只是刚开始
运行BPF程序的接口是「译者注:社区讨论」分歧的起点。驱动程序必须清楚地给正在运行的程序提供关于新数据包的信息;这是通过向BPF_PROG_RUN()传递一个SKB指针来完成的。内部机制将xdp_metadata信息的创建操作,对传入的SKB不可见。这个机制看起来足够简单明了,而且它利用了现有的BPF功能来与SKB协同工作,但是有一些反对意见。第一个反对意见是,早期丢包机制的整个目的是避免对最终都会被丢弃的数据包进行处理的开销;最初的,但并非不重要的一部分开销是创建SKB结构。无论如何都会创建SKB结构似乎有悖于最初的设计目的。
事实上,为实现这一机制而更新的驱动程序(mlx4)并没有创建一个完整的SKB;相反,它把最少的信息量放到一个假的、静态分配的SKB中。这样就避免了开销,但代价是创建了一个不是真正的SKB的SKB。需要进入这个假的SKB的信息量肯定会随着时间的推移而增加–以数据包的长度作为唯一的标准来丢弃数据包的能力,这一点出乎意料的。每当需要新的信息时,每一个驱动程序都需要调整,以提供新的信息,随着时间的推移,其结果将越来越像一个真正的SKB,而且会有相关的开销。
另一个潜在的问题是,人们对最终将BPF程序(可能在「译者注:机器码」翻译通过后)推送到网络适配器本身,有着相当大的兴趣。这样一来,数据包就可以在进入内核之前就被丢弃,进一步优化了处理过程。但是硬件不会对内核的SKB结构有任何了解,它能看到的只是数据包本身的内容。如果BPF程序被编写为期望SKB的存在,那么当推送到硬件中时,它们将无法工作。
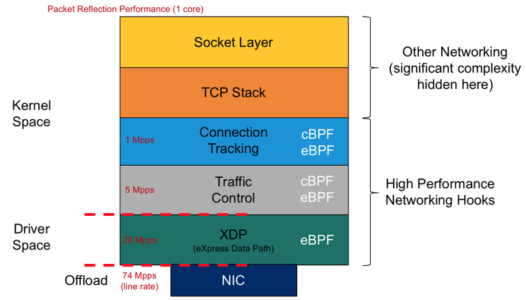
不过还有一个更大的问题:快速丢包是一个不错的能力,但高性能网络用户希望做的事情还不止这些。他们希望能够加载BPF程序来进行快速路由、在入站时重写数据包内容、执行解包、对大数据包进行卷积等等。事实上,围绕着低级别的BPF数据包处理的 “express data path”(或 “XDP”)已经有了一个完整的设想;关于开发者们的想法,请看这些幻灯片[PDF]。简而言之,他们希望提供那种优化过的处理性能,它能在保留内核堆栈和所有功能的同时,还能吸引用户使用用户空间网络堆栈。
如果要将该机制扩展到丢弃/接受(数据包)决定之外,那么显然必须增加BPF程序所能获得的信息和功能,最好是在不破坏任何现有用户的情况下。正如Alexei Starovoitov所说的那样,“我们必须对整个项目进行规划,这样我们才能在不破坏abi的情况下逐步增加功能”。目前的补丁集并没有反映出很多这种类型的规划,相反,它只是一个征求意见的帖子,介绍了XDP开发者希望在此基础上建立的机制。
所以,很明显,这个代码不会以目前的形式进入主线。但它已经取得了预期的效果,让讨论开始了;看来,人们对添加这个功能很感兴趣。如果XDP模式能够实现其性能和功能目标,那么它应该会让用户空间堆栈获得更多的收益。但要达到这个目标,还有一些重要的工作要做。
(译文完)
彩蛋——XDP第一次被合并到Linux内核的Patch Set
给大家找到了XDP第一次被merge到linux内核时的代码样子:
下面是commit message的摘要,这段摘要很好地解释了XDP的设计目的:
Brenden Blanco says: ==================== Add driver bpf hook for early packet drop and forwarding This patch set introduces new infrastructure for programmatically processing packets in the earliest stages of rx, as part of an effort others are calling eXpress Data Path (XDP). Start this effort by introducing a new bpf program type for early packet filtering, before even an skb has been allocated.