Rook带你玩转云原生存储
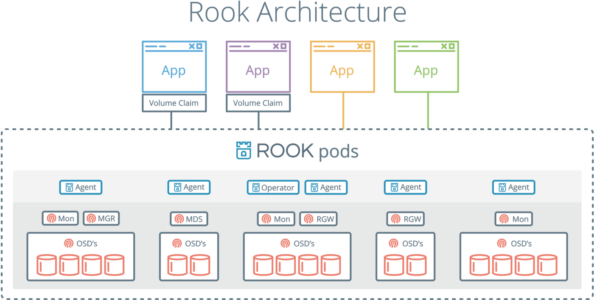
最近在研究如何实现Database as a Service,给有状态的应用提供云原生持久化存储方案是最重要的因素,来自CNCF的孵化项目Rook就映入眼帘了。
目录
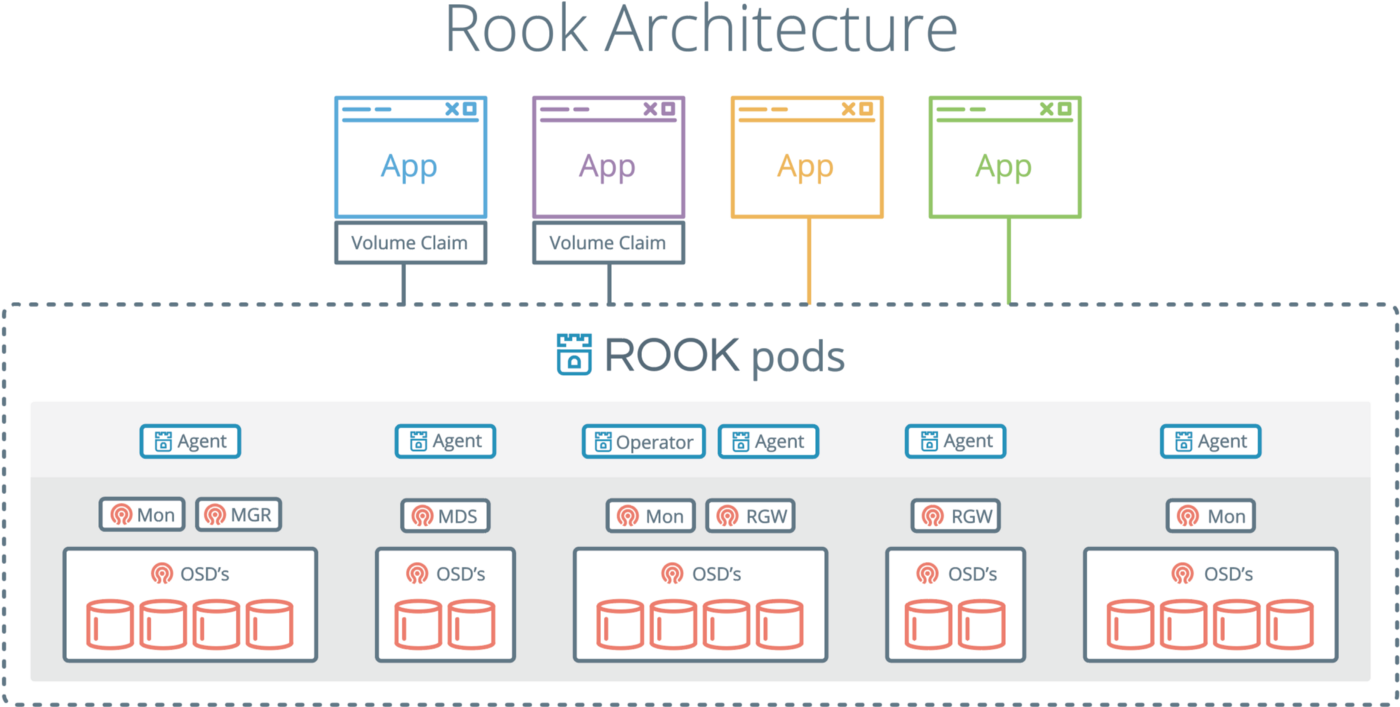
Rook是什么,要解决什么问题
First thing first,Rook is not a CSI driver. —— 首先,Rook不是一个容器存储驱动。

官方对于Rook的定义是这样的:
Rook is an open source cloud-native storage orchestrator, providing the platform, framework, and support for a diverse set of storage solutions to natively integrate with cloud-native environments.
Rook turns storage software into self-managing, self-scaling, and self-healing storage services. It does this by automating deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management. Rook uses the facilities provided by the underlying cloud-native container management, scheduling and orchestration platform to perform its duties.
Rook integrates deeply into cloud native environments leveraging extension points and providing a seamless experience for scheduling, lifecycle management, resource management, security, monitoring, and user experience.
翻译过来概况下
Rook是一个开源的云原生存储编排系统,提供平台、框架和支持,提供了一套多样化的存储解决方案,可以与云原生环境进行天然集成。Rook利用云原生容器管理、调度和调度平台提供的设施,将存储软件转化为自我管理、自我扩展和自我修复的存储服务,实现自动化部署、启动、配置、扩容、升级、迁移、灾难恢复、监控和资源管理。Rook的快速扩展的特点,深度集成到云原生环境中,并在调度、生命周期管理、资源管理、安全、监控等方面提供优异的用户体验。
因此,Rook解决的问题是:
- 快速部署一套云原生存储集群;
- 平台化管理云原生存储集群,包括存储的扩容、升级、监控、灾难恢复等全生命周期管理;
- 本身基于云原生容器管理(如Kubernetes),管理方便。
通过Rook部署Ceph集群
目前Rook支持多种存储集群的部署,包括:
- Ceph,它是一个高度可扩展的分布式存储解决方案,适用于块存储、对象存储和共享文件系统,具有多年的生产部署经验。
- EdgeFS,它是高性能和容错的分散式数据结构,可以通过对象、文件、NoSQL和块存储形式进行访问。
- Cassandra,它是一个高度可用的NoSQL数据库,具有闪电般快速的性能、灵活可控的数据一致性和大规模的可扩展性。
- CockroachDB,它是一个云原生的SQL数据库,用于构建全局性的、可扩展的云服务,可在灾难中生存。
- NFS,它允许远程主机通过网络挂载文件系统,并与这些文件系统进行交互,就像在本地挂载一样。
- YugabyteDB,是一个高性能的云端分布式SQL数据库,可以自动容忍磁盘、节点、区域和区域故障。
其中对于Ceph和EdgeFS已经是stable了,可以逐步生产使用。今天就来部署一把存储界的Super Star——Ceph。
部署前准备
官方给出了部署条件,主要是针对Kubernetes集群和节点系统层如何支持Ceph的部署条件。我这边使用的CentOS 7.6的官方系统,作了如下操作:
- 确保部署节点都安装了lvm2,可以通过
yum install lvm2安装 - 如果你跟我一样,计划使用Ceph作为rbd存储,确保部署节点都安装了rbd内核模块,可以通过
modprobe rbd检查是否已安装
部署Ceph集群
所有的部署所需的物料已经都在Rook官方的Git仓库中,建议git clone最新稳定版,然后可以参照官方文档一步步进行部署。以下是我这边的部署效果。
> git clone --single-branch --branch release-1.2 https://github.com/rook/rook.git # go to the ceph folder > cd [ur-root/path]/rook/cluster/examples/kubernetes/ceph # create service accounts, roles, role bindings > kubectl create -f common.yaml # create rook-ceph operator > kubectl create -f operator.yaml # create single-node ceph cluster for test > kubectl create -f cluster-test.yaml # Once it is completed(it took 5 mins, which depends on ur network condition), it should look like as below: # all the pods are deployed in `rook-ceph` namespace > kubectl get pod -n rook-ceph NAME READY STATUS RESTARTS AGE csi-cephfsplugin-57v4k 3/3 Running 0 6h52m csi-cephfsplugin-g5hkg 3/3 Running 0 6h52m csi-cephfsplugin-provisioner-85979bcd-fpjd2 4/4 Running 0 6h52m csi-cephfsplugin-provisioner-85979bcd-hqrsn 4/4 Running 0 6h52m csi-cephfsplugin-x7wqp 3/3 Running 0 6h52m csi-rbdplugin-dmx4c 3/3 Running 0 6h52m csi-rbdplugin-provisioner-66f64ff49c-rr2mf 5/5 Running 0 6h52m csi-rbdplugin-provisioner-66f64ff49c-wvpkg 5/5 Running 0 6h52m csi-rbdplugin-ql5bc 3/3 Running 0 6h52m csi-rbdplugin-z8s86 3/3 Running 0 6h52m rook-ceph-crashcollector-node01-df5489c87-92vqj 1/1 Running 0 6h41m rook-ceph-crashcollector-node02-679698c444-psjss 1/1 Running 0 6h47m rook-ceph-crashcollector-node03-68c85fc9bf-59ssv 1/1 Running 0 6h43m rook-ceph-mgr-a-d868c4664-vdhfx 1/1 Running 0 6h48m rook-ceph-mon-a-96cc84fc6-whb4b 1/1 Running 0 6h48m rook-ceph-operator-658dfb6cc4-rnnx6 1/1 Running 0 7h rook-ceph-osd-0-668f559469-t5m7g 1/1 Running 0 6h47m rook-ceph-osd-1-f67d67954-48mm7 1/1 Running 0 6h43m rook-ceph-osd-2-7cdf548b84-x5v6g 1/1 Running 0 6h41m rook-ceph-osd-prepare-node01-zgbn5 0/1 Completed 0 6h47m rook-ceph-osd-prepare-node02-x9lts 0/1 Completed 0 6h47m rook-ceph-osd-prepare-node03-zsz6c 0/1 Completed 0 6h47m rook-discover-2k57h 1/1 Running 0 6h52m rook-discover-8frhx 1/1 Running 0 6h52m rook-discover-jdzjz 1/1 Running 0 6h52m
部署完成后,可以通过官方提供的toolbox(就在刚才的git目录下)检查Ceph集群的健康状况:
# create ceph toolbox for check
> kubectl create -f toolbox.yaml
# enter the pod to run ceph command
> kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') -- bash
# test 1
[root@rook-ceph-tools-55d5c49f79-jkhhs /]# ceph status
cluster:
id: cda62855-74ec-4aee-9037-26445f2538ba
health: HEALTH_OK
services:
mon: 1 daemons, quorum a (age 6h)
mgr: a(active, since 6h)
osd: 3 osds: 3 up (since 6h), 3 in (since 6h)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 21 GiB used, 30 GiB / 51 GiB avail
pgs:
# test 2
[root@rook-ceph-tools-55d5c49f79-jkhhs /]# ceph osd status
+----+--------+-------+-------+--------+---------+--------+---------+-----------+
| id | host | used | avail | wr ops | wr data | rd ops | rd data | state |
+----+--------+-------+-------+--------+---------+--------+---------+-----------+
| 0 | node02 | 7332M | 9.82G | 0 | 0 | 0 | 0 | exists,up |
| 1 | node03 | 7441M | 9952M | 0 | 0 | 0 | 0 | exists,up |
| 2 | node01 | 6857M | 10.2G | 0 | 0 | 0 | 0 | exists,up |
+----+--------+-------+-------+--------+---------+--------+---------+-----------+
# test 3
[root@rook-ceph-tools-55d5c49f79-jkhhs /]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 51 GiB 30 GiB 21 GiB 21 GiB 41.45
TOTAL 51 GiB 30 GiB 21 GiB 21 GiB 41.45
POOLS:
POOL ID STORED OBJECTS USED %USED MAX AVAIL
# test 4
[root@rook-ceph-tools-55d5c49f79-jkhhs /]# rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
total_objects 0
total_used 21 GiB
total_avail 30 GiB
total_space 51 GiB
使用Ceph集群
Ceph是能提供对象存储、块存储、共享文件系统多种存储形式,这里使用块存储,兼容性更好,灵活性更高。
# go to the ceph csi rbd folder > cd [ur-root/path]/rook/cluster/examples/kubernetes/ceph/csi/rbd # create ceph rdb storageclass for test > kubectl apply -f storageclass-test.yaml cephblockpool.ceph.rook.io/replicapool created storageclass.storage.k8s.io/rook-ceph-block created > kubectl get storageclass NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 4m7s
有了Ceph StorageClass,我们只需要申明PVC,就可以快速按需创建出一个块设备以及对应的PV,相比传统的需要手动首先创建PV,然后在声明对应的PVC,操作更简单,管理更方便。
下面是一个基于Ceph StorageClass的PVC yaml例子:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ceph-pv-claim
spec:
storageClassName: rook-ceph-block # this is created sc
accessModes:
- ReadWriteOnce # pay attention to this value
resources:
requests:
storage: 1Gi
部署PVC,并观察PV是否自动创建:
> kubectl apply -f pvc.yaml persistentvolumeclaim/ceph-pv-claim created > kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ceph-pv-claim Bound pvc-fb2d6d97-d7aa-43df-808c-81f15e7a2797 1Gi RWO rook-ceph-block 3s > kubectl get pvc,pv NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE persistentvolumeclaim/ceph-pv-claim Bound pvc-fb2d6d97-d7aa-43df-808c-81f15e7a2797 1Gi RWO rook-ceph-block 9s # the pv has been created automatically and bound to the pvc we created NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE persistentvolume/pvc-fb2d6d97-d7aa-43df-808c-81f15e7a2797 1Gi RWO Delete Bound default/ceph-pv-claim rook-ceph-block 7s
创建一个基于PVC的Pod:
apiVersion: v1
kind: Pod
metadata:
name: ceph-pv-pod
spec:
volumes:
- name: ceph-pv-storage
persistentVolumeClaim:
claimName: ceph-pv-claim # use the pvc we created
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html" # mount the pv
name: ceph-pv-storage
等待Pod部署完成,观察pod的存储挂载情况:
> kubectl exec -ti ceph-pv-pod -- bash > df -h Filesystem Size Used Avail Use% Mounted on overlay 39G 4.1G 35G 11% / tmpfs 64M 0 64M 0% /dev tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup /dev/mapper/centos-root 17G 7.3G 9.8G 43% /etc/hosts /dev/mapper/centos-data 39G 4.1G 35G 11% /etc/hostname shm 64M 0 64M 0% /dev/shm # the block storage is mount to the pod /dev/rbd0 976M 2.6M 958M 1% /usr/share/nginx/html # tmpfs 1.9G 12K 1.9G 1% /run/secrets/kubernetes.io/serviceaccount tmpfs 1.9G 0 1.9G 0% /proc/acpi tmpfs 1.9G 0 1.9G 0% /proc/scsi tmpfs 1.9G 0 1.9G 0% /sys/firmware > cp -R /etc/ /usr/share/nginx/html/ # make some data into block storage
通过Ceph toolbox观察Ceph集群的使用情况:
> kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') -- bash
> ceph status
cluster:
id: cda62855-74ec-4aee-9037-26445f2538ba
health: HEALTH_OK
services:
mon: 1 daemons, quorum a (age 11h)
mgr: a(active, since 11h)
osd: 3 osds: 3 up (since 10h), 3 in (since 10h)
data:
pools: 1 pools, 8 pgs
objects: 20 objects, 21 MiB
usage: 21 GiB used, 30 GiB / 51 GiB avail
pgs: 8 active+clean
# we have some io load now
io:
client: 56 KiB/s wr, 0 op/s rd, 10 op/s wr
> ceph osd status
+----+--------+-------+-------+--------+---------+--------+---------+-----------+
| id | host | used | avail | wr ops | wr data | rd ops | rd data | state |
+----+--------+-------+-------+--------+---------+--------+---------+-----------+
| 0 | node02 | 7336M | 9.82G | 0 | 0 | 0 | 0 | exists,up |
| 1 | node03 | 7447M | 9946M | 0 | 0 | 0 | 0 | exists,up |
| 2 | node01 | 6871M | 10.2G | 0 | 0 | 0 | 819 | exists,up |
+----+--------+-------+-------+--------+---------+--------+---------+-----------+
理解Access Mode属性
存储系统的访问安全控制在Kubernetes的时代得到了长足的进步,远远胜于纯Docker时代的简单粗暴。来看下Kubernetes在管理存储(PV、PVC)时提供了哪些访问控制机制:
- RWO: ReadWriteOnce,只有单个节点可以挂载这个volume,进行读写操作;
- ROX: ReadOnlyMany,多个节点可以挂载这个volume,只能进行读操作;
- RWX: ReadWriteMany,多个节点可以挂载这个volume,读写操作都是允许的。
所以RWO、ROX和RWX只跟同时使用volume的worker节点数量有关,而不是跟pod数量!
以前苦于没有部署云原生存储系统,一直没法实践这些特性,这次得益于Rook的便捷性,赶紧来尝鲜下。计划测试两个场景:
- 测试ReadWriteOnce,测试步骤如下:
- 首先部署一个使用ReadWriteOnce访问权限的PVC的名为ceph-pv-pod的单个pod实例
- 然后部署一个使用相同PVC的名为n2的deployment,1个pod实例
- 扩容n2至6个pod副本
- 观察结果
> kubectl get pod -o wide --sort-by=.spec.nodeName | grep -E '^(n2|ceph)' NAME READY STATUS IP NODE n2-7db787d7f4-ww2fp 0/1 ContainerCreating <none> node01 n2-7db787d7f4-8r4n4 0/1 ContainerCreating <none> node02 n2-7db787d7f4-q5msc 0/1 ContainerCreating <none> node02 n2-7db787d7f4-2pfvd 1/1 Running 100.96.174.137 node03 n2-7db787d7f4-c8r8k 1/1 Running 100.96.174.139 node03 n2-7db787d7f4-hrwv4 1/1 Running 100.96.174.138 node03 ceph-pv-pod 1/1 Running 100.96.174.135 node03
从上面的结果可以看到,由于ceph-pv-pod这个Pod优先绑定了声明为ReadWriteOnce的PVC,它所在的节点node03就能成功部署n2的pod实例,而调度到其他节点的n2就无法成功部署了,挑个看看错误信息:
> kubectl describe pod n2-7db787d7f4-ww2fp ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled <unknown> default-scheduler Successfully assigned default/n2-7db787d7f4-ww2fp to node01 Warning FailedAttachVolume 10m attachdetach-controller Multi-Attach error for volume "pvc-fb2d6d97-d7aa-43df-808c-81f15e7a2797" Volume is already used by pod(s) n2-7db787d7f4-c8r8k, ceph-pv-pod, n2-7db787d7f4-2pfvd, n2-7db787d7f4-hrwv4
从Pod Events中可以明显看到错误了,由于ReadWriteOnce的存在,无法使用Multi-Attach了,符合期待。
- 测试ReadWriteMany,测试步骤如下:
- 首先部署一个使用 ReadWriteMany访问权限的PVC的名为2ceph-pv-pod的单个pod实例
- 然后部署一个使用相同PVC的名为n3的deployment,1个pod实例
- 扩容n3至6个pod副本
- 观察结果
原来是想直接改第一个测试场景的创建pvc的yaml,发现如下错误。意思是创建好的pvc除了申请的存储空间以外,其他属性是无法修改的。
> k apply -f pvc.yaml The PersistentVolumeClaim "ceph-pv-claim" is invalid: spec: Forbidden: is immutable after creation except resources.requests for bound claims
只能重新创建了。。。但当声明创建新的PVC时,又发生了问题,pvc一直处于pending状态。。。
> kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ceph-pv-claim Bound pvc-fb2d6d97-d7aa-43df-808c-81f15e7a2797 1Gi RWO rook-ceph-block 36h ceph-pvc-2 Pending rook-ceph-block 10m > kubectl describe pvc ceph-pvc-2 ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Provisioning 4m41s (x11 over 13m) rook-ceph.rbd.csi.ceph.com_csi-rbdplugin-provisioner-66f64ff49c-wvpkg_b78217fb-8739-4ced-9e18-7430fdde964b External provisioner is provisioning volume for claim "default/ceph-pvc-2" Warning ProvisioningFailed 4m41s (x11 over 13m) rook-ceph.rbd.csi.ceph.com_csi-rbdplugin-provisioner-66f64ff49c-wvpkg_b78217fb-8739-4ced-9e18-7430fdde964b failed to provision volume with StorageClass "rook-ceph-block": rpc error: code = InvalidArgument desc = multi node access modes are only supported on rbd `block` type volumes Normal ExternalProvisioning 3m4s (x42 over 13m) persistentvolume-controller waiting for a volume to be created, either by external provisioner "rook-ceph.rbd.csi.ceph.com" or manually created by system administrator
查看event详细后,发现了这个错误信息:
failed to provision volume with StorageClass "rook-ceph-block": rpc error: code = InvalidArgument desc = multi node access modes are only supported on rbd `block` type volumes
翻译过来的意思是:多节点访问模式只支持在rbd block类型的volume上配置。。。难道说ceph的这个rbd storageclass是个假的“块存储”。。。
一般发生这种不所措的错误,首先可以去官方Github的issue或pr里找找有没有类似的问题。经过一番搜索,找到一个maintainer的相关说法。如下图所示。意思是不推荐在ceph rbd模式下使用RWX访问控制,如果应用层没有访问锁机制,可能会造成数据损坏。
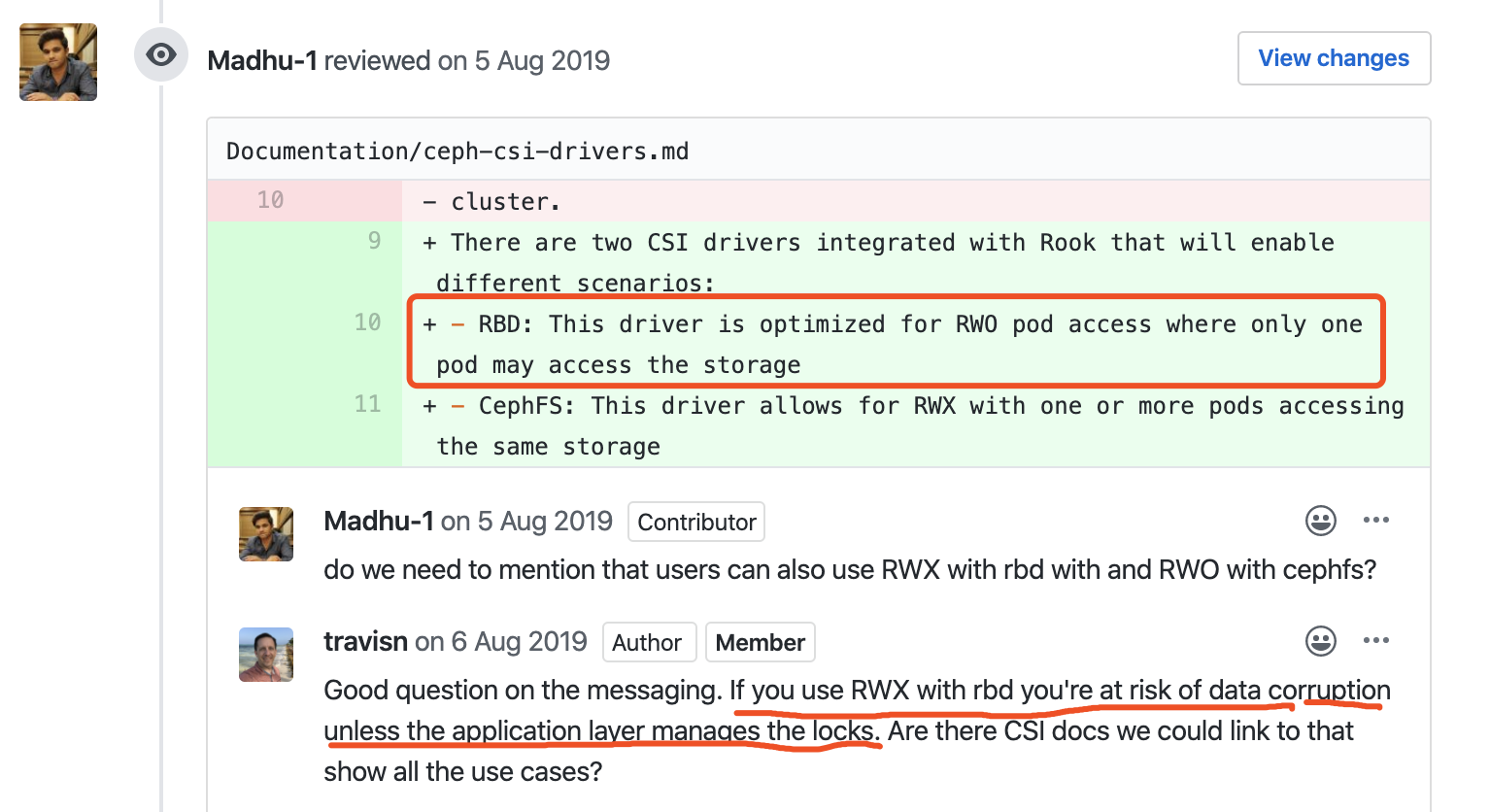
进而找到了官方上的说法
There are two CSI drivers integrated with Rook that will enable different scenarios:
- RBD: This driver is optimized for RWO pod access where only one pod may access the storage
- CephFS: This driver allows for RWX with one or more pods accessing the same storage
好吧,原来官方网站已经说明了CephFS模式是使用RWX模式的正确选择。
使用CephFS测试ReadWriteMany(RWX)模式
官方已经提供了支持CephFS的StorageClass,我们需要部署开启:
> cd [ur-rook-git]/rook/cluster/examples/kubernetes/ceph/csi/cephfs/ > kubectl apply -f storageclass.yaml > kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION csi-cephfs rook-ceph.cephfs.csi.ceph.com Delete Immediate true rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true
注意观察上面的StorageClass文件parameters里有一行:
# CephFS filesystem name into which the volume shall be created
fsName: myfs
这是使用CephFS必须要有的文件系统,必须创建好,才能声明创建基于CephFS的PV和PVC。官方提供了示例:
> cat cephfs-filesystem.yaml
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: myfs # the name should be the same as the one in storageclass yaml
namespace: rook-ceph
spec:
metadataPool:
replicated:
size: 3
dataPools:
- replicated:
size: 3
preservePoolsOnDelete: true
metadataServer:
activeCount: 1
activeStandby: true
> kubectl apply -f cephfs-filesystem.yaml
创建完CephFS的StorageClass和FileSystem,就可以测试了。测试场景为部署一个deployment,6个副本,使用RWX模式的Volume:
# pvc-cephfs.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cephfs-pvc
spec:
storageClassName: csi-cephfs # new storageclass
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
---
# deployment-cephfs-pvc.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: n4-cephfs
pv: cephfs
name: n4-cephfs
spec:
replicas: 3
selector:
matchLabels:
app: n4-cephfs
pv: cephfs
template:
metadata:
labels:
app: n4-cephfs
pv: cephfs
spec:
volumes:
- name: fsceph-pv-storage
persistentVolumeClaim:
claimName: cephfs-pvc
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: fsceph-pv-storage
部署后观察每个pod的运行情况以及PV和PVC创建情况:
> kubectl get pod -l pv=cephfs -o wide NAME READY STATUS IP NODE n4-cephfs-859b956b65-768z7 1/1 Running 100.95.185.225 node02 n4-cephfs-859b956b65-cs9jn 1/1 Running 100.96.174.143 node03 n4-cephfs-859b956b65-rwdn4 1/1 Running 100.117.144.146 node01 n4-cephfs-859b956b65-x55s4 1/1 Running 100.96.174.142 node03 n4-cephfs-859b956b65-xffwb 1/1 Running 100.117.144.148 node01 n4-cephfs-859b956b65-xx8nz 1/1 Running 100.117.144.147 node01 > > kubectl get pvc,pv NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS persistentvolumeclaim/cephfs-pvc Bound pvc-75b40dd7-b880-4d67-9da6-88aba8616466 1Gi RWX csi-cephfs NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS persistentvolume/pvc-75b40dd7-b880-4d67-9da6-88aba8616466 1Gi RWX Delete Bound default/cephfs-pvc csi-cephfs
分布在不同的节点上的pod都能部署成功,PV也能创建绑定成功。符合测试预期。
更深入地观察存储挂载机制
通过上面两个测试场景,我们来看下背后的云原生存储的运行逻辑:
- 进入pod观察存储挂载情况
对比两个测试场景pod实例里面存储挂载情况:
# use ceph as rbd storage # it is mount as block device > df -h /dev/rbd0 976M 3.3M 957M 1% /usr/share/nginx/html # use ceph as file system storage # it is mount as nfs storage > df -h 10.109.80.220:6789:/volumes/csi/csi-vol-1dc92634-79cd-11ea-96a3-26ab72958ea2 1.0G 0 1.0G 0% /usr/share/nginx/html
可以看到Ceph rbd和CephFS挂载到Pod里的方式是有差别的。
- 观察主机层存储挂载情况
# use ceph as rbd storage > df -h |grep rbd # on work node /dev/rbd0 976M 3.3M 957M 1% /var/lib/kubelet/pods/e432e18d-b18f-4b26-8128-0b0219a60662/volumes/kubernetes.io~csi/pvc-fb2d6d97-d7aa-43df-808c-81f15e7a2797/mount # use ceph as file system storage > df -h |grep csi 10.109.80.220:6789:/volumes/csi/csi-vol-1dc92634-79cd-11ea-96a3-26ab72958ea2 1.0G 0 1.0G 0% /var/lib/kubelet/plugins/kubernetes.io/csi/pv/pvc-75b40dd7-b880-4d67-9da6-88aba8616466/globalmount
简单解释下主机层相关路径的命名规则:
/var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字>
最终都是通过docker run映射到容器里去:
docker run -v /var/lib/kubelet/pods/<Pod-ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字>:/<容器内目标目录> 镜像 ...
- 从Kubernetes观察存储挂载情况
Kubernetes提供了获取StorageClass、PV和Node之间的关系——volumeattachment资源类型。它的官方解释是:
VolumeAttachment captures the intent to attach or detach the specified volume to/from the specified node. VolumeAttachment objects are non-namespaced.
来看下当前的情况:
> kubectl get volumeattachment NAME ATTACHER PV NODE ATTACHED AGE csi-0453435f600da9580d6dff3bceb3d151d36462fa001c682663dd7371beff309f rook-ceph.cephfs.csi.ceph.com pvc-75b40dd7-b880-4d67-9da6-88aba8616466 node02 true 13h csi-89e8c56d49e524d5d8dd6bfe4809f040f35f8b416a09241bcb9e6632ced232be rook-ceph.cephfs.csi.ceph.com pvc-75b40dd7-b880-4d67-9da6-88aba8616466 node03 true 13h csi-97bab907614b96ddf2df6ce15d547e409b68bb41591f1b4bd25eacb9a59ec9de rook-ceph.rbd.csi.ceph.com pvc-fb2d6d97-d7aa-43df-808c-81f15e7a2797 node03 true 2d3h csi-f002b45a7930af0b144fd0d40734ec3a41a207b892db471cb82d373b9bfd79bd rook-ceph.cephfs.csi.ceph.com pvc-75b40dd7-b880-4d67-9da6-88aba8616466 node01 true 13h
能看到每个主机层挂载点的详细情况,方便大家troubleshooting。
Ceph界面化管理Ceph Dashboard
Rook官方很贴心地提供了Ceph界面化管理的解决方案——Ceph dashboard。标准版部署Rook已经自带这个功能,默认是无法集群外访问的,手动expose为nodeport模式即可:
> kubectl -n rook-ceph get svc |grep dash rook-ceph-mgr-dashboard ClusterIP 10.97.126.41 <none> 8443/TCP 2d14h rook-ceph-mgr-dashboard-external-https NodePort 10.109.153.31 <none> 8443:30010/TCP 14h
通过浏览器访问https://node-ip:30010,默认登录用户名为admin,密码可以通过这样的方式获取:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
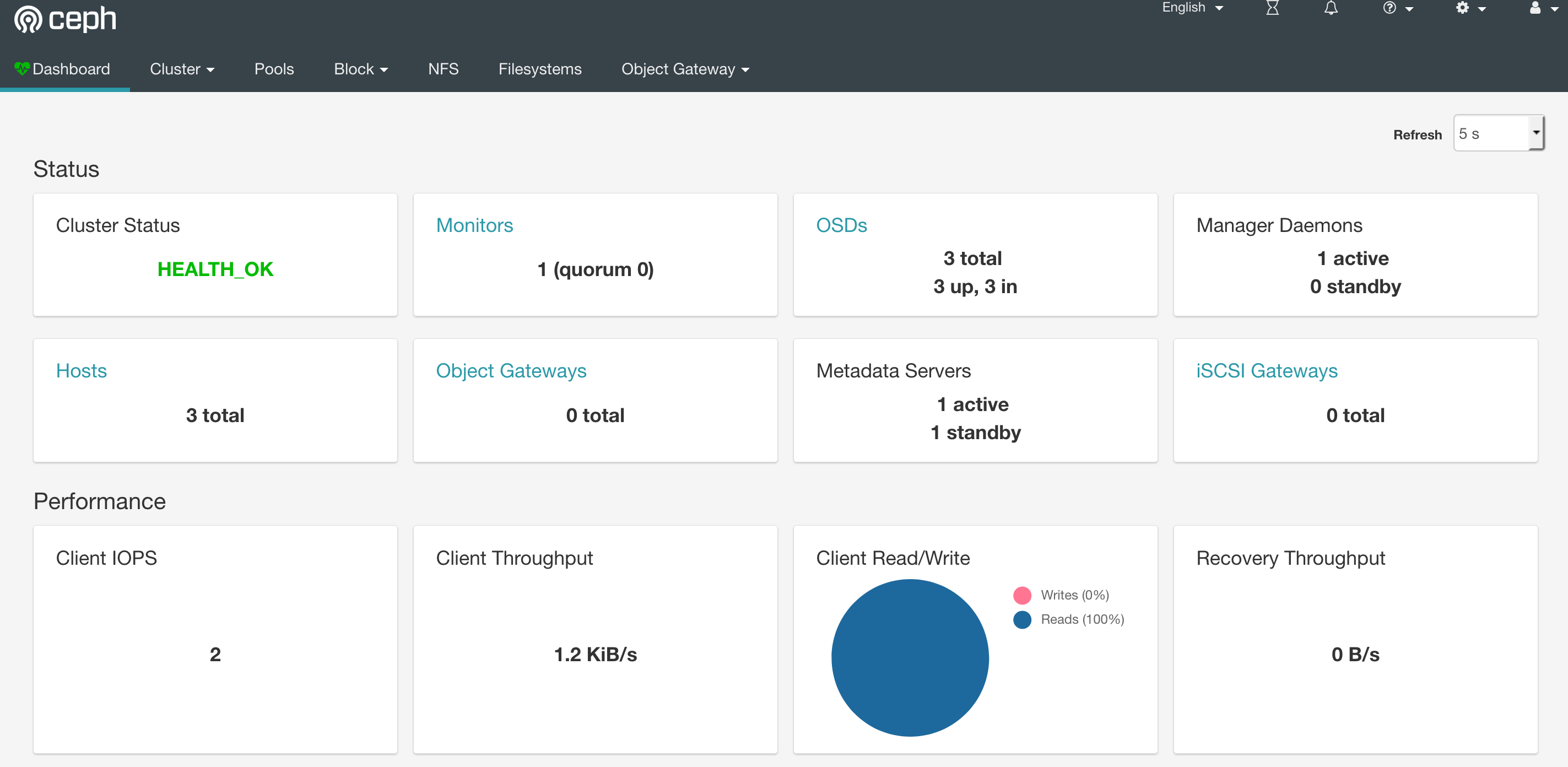
登录后,界面如下。内容非常多,包括读写速率监控,健康监控等,绝对是Ceph管理的好帮手。
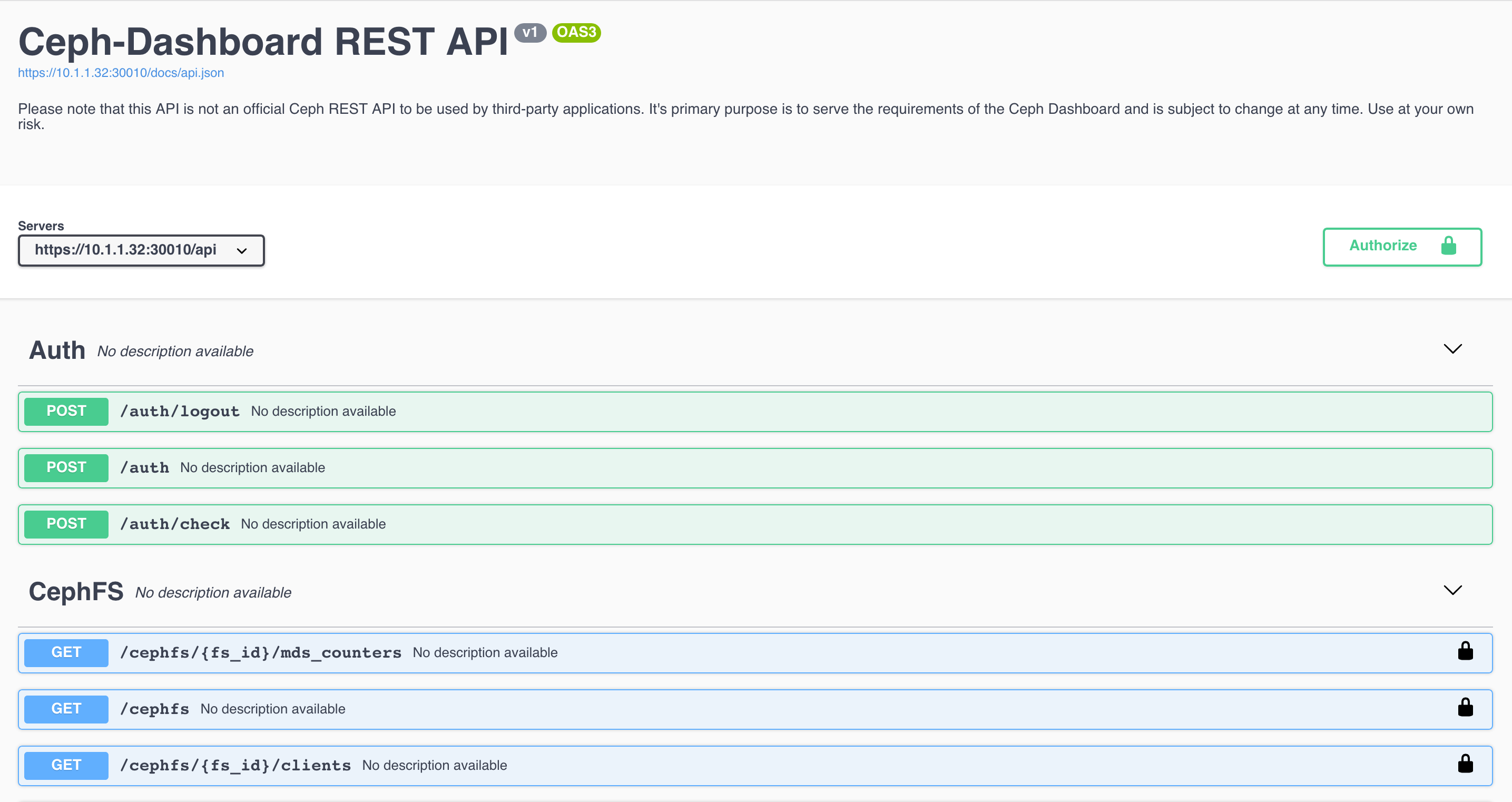
还提供交互式API文档,非常贴心。
戳视频可以看完整Demo:
总结
Rook能帮你快速搭建一套Production-Ready的云原生存储平台,同时提供全生命周期管理,适合初中高级全阶段的存储管理玩家。
本文涉及的部署物料可以去这里获取:
Rook Rocks