eBPF文章翻译(1)—eBPF介绍
eBPF学习计划可以看这里,
该篇为入门文章翻译系列第一篇,第二篇介绍BCC看这里。
原文名称:A thorough introduction to eBPF,原文地址:https://lwn.net/Articles/740157/
Brendan Gregg,他在2017年的linux.conf.au大会上的演讲提到「内核虚拟机eBPF」,表示,”超能力终于来到了Linux操作系统“。让eBPF达到这一点是一条漫长的进化和设计之路。虽然eBPF最初用于网络包过滤,但事实证明,对于内核开发人员和生产工程师来说,在一个可以进行健康检查的虚拟机中运行用户态代码,能成为一个强大的工具。随着时间的推移,越来越多新的eBPF用户开始利用它的高性能和便利性。本文解释了eBPF是如何演进,如何工作,以及如何在内核中使用它。
目录
eBPF的演变
原始的 bpf是设计用来抓取和过滤符合特定规则的网络包。过滤器是通过程序实现的,并在基于寄存器的虚拟机上运行。
在内核内部运行用户提供的程序的能力,被证明是一个有用的设计决策,但是原始BPF设计的其他方面并没有保持地很好。举个例子,随着现代处理器转移到64位寄存器,并发明了多核处理器系统所需的新指令,原始的虚拟机设计和指令集结构(ISA)已经过时,比如原子交换-添加指令(XADD)。BPF专注于提供少量的RISC指令的特点,已不再与现代处理器的实际情况相匹配。
因此,Alexei Starovoitov为了更好地利用的现代硬件,提出了扩展型BPF(eBPF)设计。eBPF虚拟机更类似于现代的处理器,允许eBPF指令映射到更贴近硬件的ISA以获得更好的性能。最显著的变化之一是转向使用64位寄存器,以及提升使用寄存器数量,从2个增加到10个。由于现代体系结构拥有远超过两个的寄存器数量,因此允许将参数传递给eBPF虚拟机寄存器中的函数,就像在原生的硬件上一样。另外,新的BPF_CALL指令,可以更廉价地调用内核函数。
将eBPF映射到原生指令的易用性,有助于即时编译,从而提高了性能。3.15内核最早添加对eBPF支持的原始补丁,对于某些网络过滤器微基准测试上显示,eBPF在 x86-64架构上的速度比旧的经典BPF (cBPF)实现最高快四倍,大多数都在1.5倍。许多硬件架构支持了即时编译器(x86-64, SPARC, PowerPC, ARM, arm64, MIPS, 和 s390)。
最初,eBPF只在内核内部使用,而cBPF程序也是在底层无缝转换的。但是在2014年的daedfb22451d这次代码提交中,eBPF虚拟机直接暴露给了用户空间来调用。
你能用eBPF做什么
eBPF程序被“附加”到内核中指定的代码路径。当代码路径被遍历到时,任何附加的eBPF程序都会被执行。由于eBPF的起源,它特别适合编写网络程序,并且可以编写程序,附加到网络套接字来过滤流量,对流量进行分类,并执行网络分类器动作。甚至可以使用eBPF程序修改已建立的网络套接字的设置。XDP这个项目就是专门使用eBPF来执行高性能数据包处理,方法是在收到数据包之后,立即在网络栈的最低层执行eBPF程式。
另一种内核处理的过滤类型,是限制一个进程可以使用的系统调用方法。这是用seccomp BPF实现的。
eBPF对于调试内核和执行性能分析也很有用;程序可以被附加到跟踪点、kprobes和perf事件。因为eBPF程序可以访问内核的数据结构,所以开发人员可以编写和测试新的调试代码,而不必重新编译内核。这对于在实时运行系统上调试问题的繁忙工程师来说,作用是显而易见的。甚至可以使用eBPF通过「用户空间静态定义的跟踪点」来调试用户空间程序。
eBPF的强大之处在于它的两个优点:快速和安全。要完全欣赏它,你需要了解它是如何运作的。
eBPF内核验证器
允许用户空间代码在内核中运行,是存在固有的安全性和稳定性风险的。因此,在加载每个eBPF程序之前,都要执行一定数量的检查测试。第一个测试是确保eBPF程序终止时,不包含任何可能导致内核锁定的循环逻辑,这点是通过对程序的控制流图(CFG)进行深度优先搜索来检查的。严禁使用不可达的指令;任何包含不可达指令的程序都将无法加载。
第二阶段更为复杂,需要验证器模拟执行eBPF程序,每次一条指令。在执行每条指令之前和之后检查虚拟机状态,以确保寄存器和堆栈状态是有效的。禁止越界跳转,也禁止访问越界数据。
验证器不需要遍历程序中的每条路径,因为它足够智能,知道当前程序的状态是已经被检查过程序的子集。因为之前的所有路径都必须是有效的(否则程序就已经加载失败了),当前路径必须也是有效的。这允许验证器“裁剪”当前分支并跳过其模拟验证过程。
验证器还有一个禁止指针运算的“安全模式”。当没有使用CAP_SYS_ADMIN特权选项加载eBPF程序时,就会启用安全模式。其思想是确保内核地址不会泄漏给没有特权的用户,并且指针不能写入内存。如果未启用安全模式,则允许指针运算,但必须在执行附加检查之后。例如,检查所有指针访问的类型、位置和边界违反情况。
无法读取具有未初始化内容(那些从未被写入的内容)的寄存器;这么做会导致程序加载失败。寄存器R0-R5的内容在函数调用时会被标记为不可读,方法是存储一个特殊的值来捕获任何读取未初始化寄存器的操作。对读取栈上的变量也进行了类似的检查,以确保没有指令写入只读类型的帧指针寄存器。
最后,验证器使用eBPF程序类型(后面将介绍)来限制可以从eBPF程序调用哪些内核函数以及可以访问哪些数据结构。例如,某些程序类型可以直接访问网络包数据。
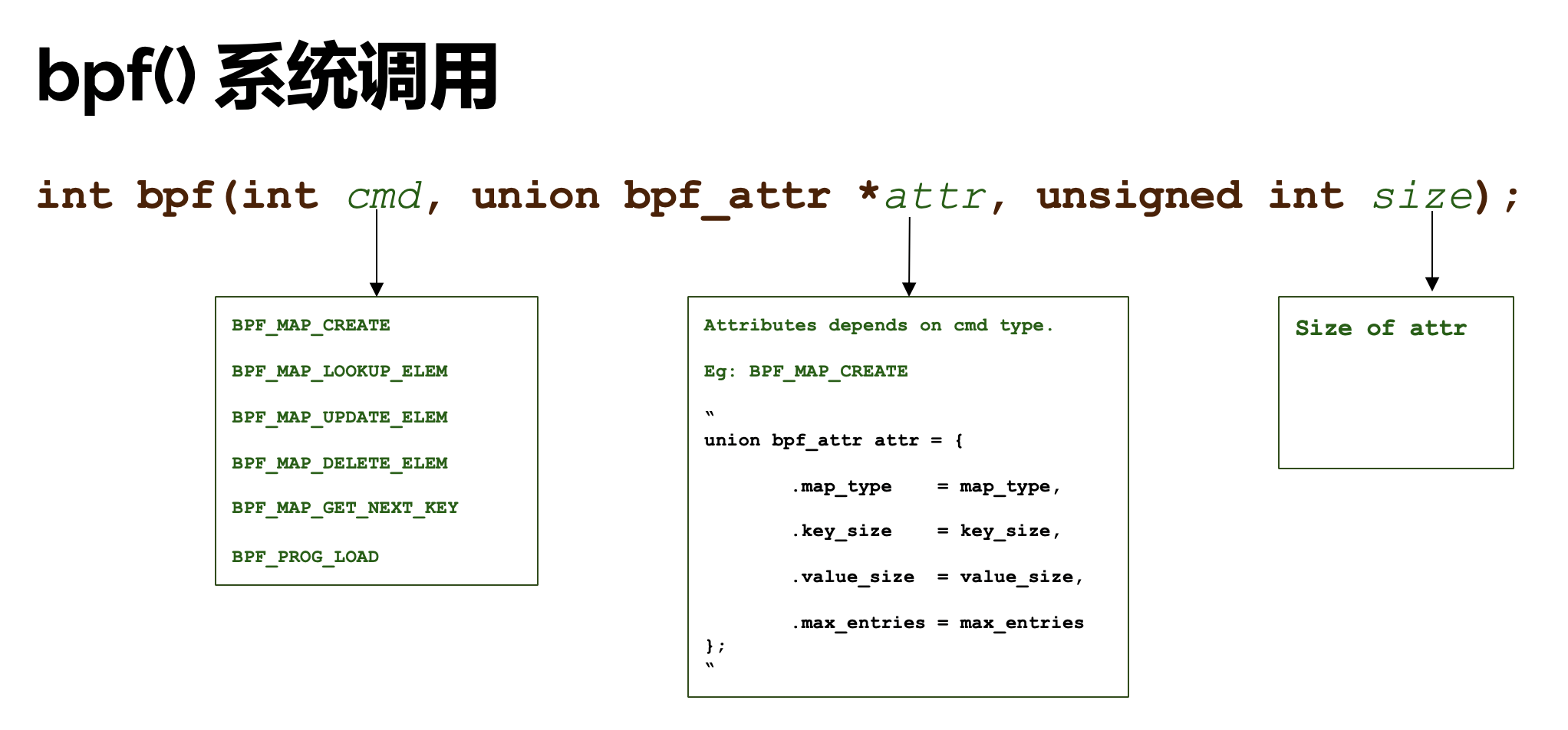
系统调用函数bpf()
使用bpf()这个系统调用函数配合BPF_PROG LOAD命令来加载程序。它的原型是:
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
bpf_attr union 允许在内核和用户空间之间传递数据;确切的格式取决于 cmd 这个参数。size 这个参数表示bpf_attr union 这个对象以字节为单位的大小。
可以使用命令创建和修改eBPF maps数据结构,这个数据结构一个通用键值对数据结构,用于在eBPF程序和内核或用户空间之间通信的。附加命令允许将eBPF程序附加到控制组目录或套接字文件描述符,遍历所有map键值对和程序,并将eBPF对象保存到文件中,以便加载它们的进程终止时,不会销毁它们(后者使用了分类器tc的代码,因此eBPF程序无需加载过程持续运行就可以持久化。全部命令列表可以在bpf() man手册中找到。
虽然有许多不同的命令,但它们可以被分成三类:使用eBPF程序的命令,使用eBPF maps的命令,或同时使用程序和maps的命令(统称为对象)。
eBPF程序类型
函数BPF_PROG_LOAD加载的程序类型规定了四件事:程序可以附加在哪里,验证器允许调用内核中的哪些帮助函数,网络包的数据是否可以直接访问,作为第一个参数传递给程序的对象类型。实际上,程序类型本质上定义了一个API。甚至还创建了新的程序类型,以区分允许调用的不同的函数列表(比如BPF_PROG_TYPE_CGROUP_SKB 对比 BPF_PROG_TYPE_SOCKET_FILTER)。
目前内核支持的eBPF程序类型列表如下所示:
BPF_PROG_TYPE_SOCKET_FILTER: 一种网络数据包过滤器BPF_PROG_TYPE_KPROBE: 确定kprobe是否应该触发BPF_PROG_TYPE_SCHED_CLS: 一种网络流量控制分类器BPF_PROG_TYPE_SCHED_ACT: 一种网络流量控制动作BPF_PROG_TYPE_TRACEPOINT: 确定 tracepoint是否应该触发BPF_PROG_TYPE_XDP: 从设备驱动程序接收路径运行的网络数据包过滤器BPF_PROG_TYPE_PERF_EVENT: 确定是否应该触发perf事件处理程序BPF_PROG_TYPE_CGROUP_SKB: 一种用于控制组的网络数据包过滤器BPF_PROG_TYPE_CGROUP_SOCK: 一种由于控制组的网络包筛选器,它被允许修改套接字选项BPF_PROG_TYPE_LWT_*: 用于轻量级隧道的网络数据包过滤器BPF_PROG_TYPE_SOCK_OPS: 一个用于设置套接字参数的程序BPF_PROG_TYPE_SK_SKB: 一个用于套接字之间转发数据包的网络包过滤器BPF_PROG_CGROUP_DEVICE: 确定是否允许设备操作
随着新程序类型的添加,内核开发人员同时发现也需要添加新的数据结构。
eBPF 数据结构
eBPF程序使用的主要数据结构是eBPF map(键值对)数据结构,这是一种通用的数据结构,允许在内核内部或内核与用户空间之间来回传递数据。正如名称“map”所暗示的,数据是使用键存储和检索的。
使用bpf()系统调用创建和操作map数据结构。成功创建map后,将返回与该map关联的文件描述符。每个map由四个值定义:类型、元素的最大个数、值大小(以字节为单位)和键大小(以字节为单位)。有不同的map类型,每种类型都提供不同的行为和一些权衡:
BPF_MAP_TYPE_HASH: 一种哈希表BPF_MAP_TYPE_ARRAY: 一种为快速查找速度而优化的数组类型map键值对,通常用于计数器BPF_MAP_TYPE_PROG_ARRAY: 与eBPF程序相对应的一种文件描述符数组;用于实现跳转表和处理特定(网络)包协议的子程序BPF_MAP_TYPE_PERCPU_ARRAY: 一种基于每个cpu的数组,用于实现展现延迟的直方图BPF_MAP_TYPE_PERF_EVENT_ARRAY: 存储指向perf_event数据结构的指针,用于读取和存储perf事件计数器BPF_MAP_TYPE_CGROUP_ARRAY: 存储指向控制组的指针BPF_MAP_TYPE_PERCPU_HASH: 一种基于每个CPU的哈希表BPF_MAP_TYPE_LRU_HASH: 一种只保留最近使用项的哈希表BPF_MAP_TYPE_LRU_PERCPU_HASH: 一种基于每个CPU的哈希表,只保留最近使用项BPF_MAP_TYPE_LPM_TRIE: 一个匹配最长前缀的字典树数据结构,适用于将IP地址匹配到一个范围BPF_MAP_TYPE_STACK_TRACE: 存储堆栈跟踪信息BPF_MAP_TYPE_ARRAY_OF_MAPS: 一种map-in-map数据结构BPF_MAP_TYPE_HASH_OF_MAPS: 一种map-in-map数据结构BPF_MAP_TYPE_DEVICE_MAP: 用于存储和查找网络设备的引用BPF_MAP_TYPE_SOCKET_MAP: 存储和查找套接字,并允许使用BPF帮助函数进行套接字重定向
可以使用bpf_map_lookup_elem()函数和bpf_map_update_elem()函数从eBPF程序或用户空间程序访问所有map对象。某些map类型,如套接字类型map,它是与那些执行特殊任务的eBPF帮助函数,一起工作。
如何编写一个eBPF程序
以前,必须通过手工编写eBPF汇编代码,并使用内核的bpf_asm汇编程序来生成BPF字节码。幸运的是,LLVM Clang编译器增加了对eBPF后端的支持,现在可以将C语言写的程序通过LLVM Clang编译器,编译成字节码。然后可以使用bpf()系统调用函数和BPF_PROG_LOAD命令,直接加载包含这个字节码的对象文件。
通过使用Clang编译器,配合-march=bpf参数,您就可以用C语言编写自己的eBPF程序了。在内核代码的 samples/bpf/ 目录下有很多eBPF程序的示例,它们的文件名称大部分都具有「_kern.c」的后缀。Clang编译出来的目标文件(eBPF字节码),需要由在本机运行的一个程序进行加载(这些示例的文件名称中通常具有「_user.c」)。为了更容易地编写eBPF程序,内核提供了libbpf库,其中包括用于加载程序、创建和操作eBPF对象的帮助函数。举个例子,一个eBPF程序和使用libbpf库的用户程序的抽象的工作流程一般像如下这样的:
- 读取eBPF字节码到用户应用程序中的缓冲区,并将其传递给
bpf_load_program()函数 - eBPF程序,当在内核运行时,它将调用
bpf_map_lookup_elem()函数来查找map中的元素,并存储新值给这个元素。 - 用户应用程序调用
bpf_map_lookup_elem()函数来读取eBPF程序存储在内核中的值。
但是,上面提到的所有的样例代码都有一个主要缺点:您需要从内核源代码树中编译你的eBPF程序。幸运的是,BCC项目就是为了解决这个问题而诞生的。它包括一个完整的工具链,用于编写eBPF程序,并在不不要链接内核源代码树的情况下加载它们。
本系列的下一篇文章将讨论BCC项目,全部文章的链接如下所示:
- An introduction to the BPF Compiler Collection
- Some advanced BCC topics
- User-space tracepoints with BPF
后记——翻译小结
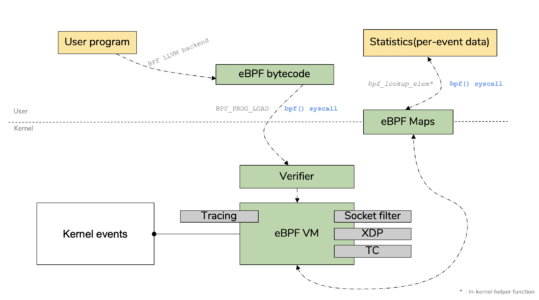
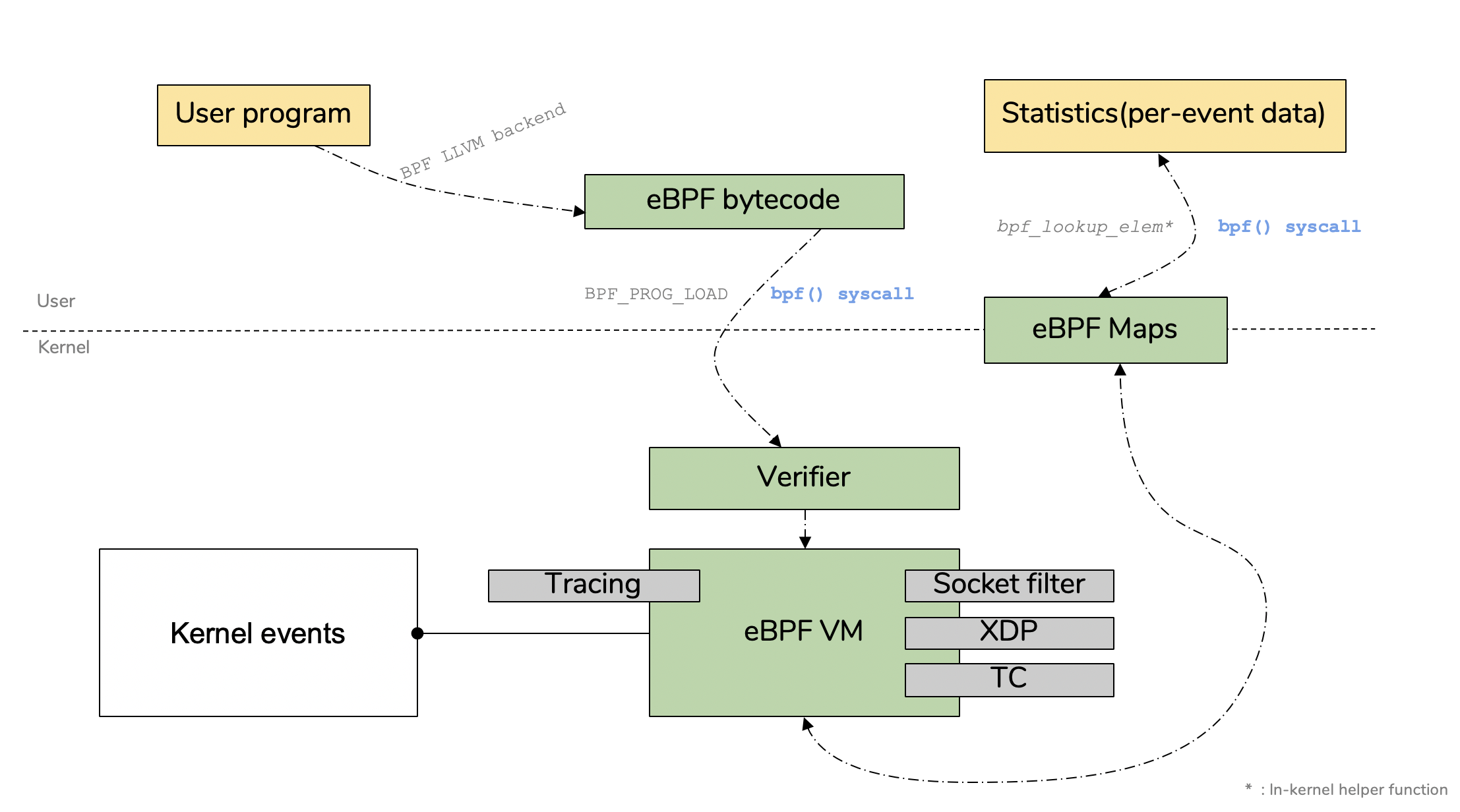
- eBPF工作流程图如下所示:
- 系统调用bpf()简析
eBPF流程图中有个错误吧。
perf event不是以BPF map方式发送给用户态的,是走perf缓冲区,单项从内核态发送到用户态的。